Joey Xu
Saturday, April 4, 2020
helm 部署Prometheus-Operator
监控基本知识
常用监控方法:(在文章中会持续穿插以下方法的使用)
(1) USE方法: 即使用率(Utilization),饱和度(Staturation),错误(Error),针对于每个资源,检查使用率饱和度和错误,侧重于主机层面监控
资源: 系统的组件,例如CPU,内存,IO等
使用率: 资源处理工作的平均时间,通常为百分比表示
饱和度: 资源排队工作的指标, 通常为队列长度表示
错误: 资源错误事件的计数
将以上结合起来创建一份资源清单,并采用一种方法来监控每个要素,例如系统性能出现瓶颈时,我们可以参考以下要素:
1:CPU的清单
CPU使用率随时间的百分比
CPU饱和度,等待CPU的进程数
CPU错误(比较少)
2:内存的清单
内存使用率随时间的百分比
内存饱和度,通过监控swap测量
内存错误(比较少)
其他Linux系统资源的示例可以参考BrenDan Gregg所提供的清单
(2) Google的四个黄金指标: 延迟, 流量, 错误, 饱和度, 更多是针对于应用程序或面向用户部分, 依次选择对应的指标设置报警
延迟: 服务请求所花费的时间, 而成功请求和失败请求有所区别, 例如失败请求会以很低的延迟返回错误的结果
流量: 针对系统,例如每秒HTTP请求数或数据库系统的事务
错误: 请求失败的速率, 例如HTTP 500错误等显示失败, 返回错误内容或无效内容的隐式失败或者强制要求相应时间超过30s的请求视为错误的基于策略原因的失败
饱和度: 应用程序处理极限或系统资源极限,例如到达程序最大处理请求数量或内存cpu等资源饱和
通常监控应用程序主要有两种方法:
黑盒监控:查询程序外部特征,例如端口是否正常,数据或状态码返回是否正常,或者执行ICMP检查服务器是否正常
例如ping服务器,telnet端口号,curl状态码等
白盒监控:主要查看程序内部特征, 例如应用程序检查后所返回其状态,内部组件或事务和事件性能的度量,将事件,日志和指标发送到监控工具
例如redis的info中显示redis slave down, mysql使用show variables暴露内部指标信息,httpd使用mod_status来暴露内部信息等
报警和通知
告警和通知是监控工具的主要输出方式,一个出色的通知系统需包含以下基础信息:
(1) 哪些问题需要通知
(2) 哪些人要被告知
(3) 哪些方法告知
(4) 多久告知一次
(5) 何时停止告知及何时升级告知其他人
配置不当会造成通知泛滥,忽略重要信息,且通知内容应简洁,清晰,准确,易于理解并可操作
Prometheus简介
Prometheus源于谷歌的Borgmon,专注于提供近实时的,基于动态云环境和容器的微服务和应用的白盒监控(主要)
Prometheus架构
Prometheus通过抓取或拉取应用程序中暴漏的时间序列数据来工作(通常有应用程序本身通过客户端库或export的代理来作为HTTP端点暴漏) Prometheus有一个Push Gateway,用于接收少量数据,例如来自无法拉取的目标数据
架构图如下:

组件说明:
Prometheus Server: 用于收集和存储时间序列数据
Client Library: 客户端库,为需要监控的服务生成相应的 metrics 并暴露给 Prometheus server
Push Gateway: 主要用于短时间的 jobs,由于这类 jobs 存在时间较短,可能在 Prometheus 来 pull 之前就消失了
metrics,对于机器层面的 metrices,需要使用 node exporter
Exporters: 负责监控机器运行状态,提供被监控组件信息的 HTTP 接口被叫做 exporter
Alertmanager: 从 Prometheus server 端接收到 alerts 后,会进行去除重复数据,分组,并路由到对收的接受方式,发出报警
生成的时间序列数据被收集存储到本地或者其他存储器或时间序列数据库
指标收集
端点(endpoint): Prometheus抓取指标的来源,通常为单个进程,主机,服务或应用程序
目标(target): 执行抓取端点数据所需的配置,例如如何连接,要应用哪些元数据
作业(job): 相同角色的目标组(例如后端一组tomcat的服务器)
实例(instance): 每个job都有一个名为实例的标签用来唯一标识这个目标
Prometheus-Operator架构
Prometheus Operator 是 CoreOS 开源的用来管理在 Kubernetes 上的 Prometheus的控制器,其架构图如下:
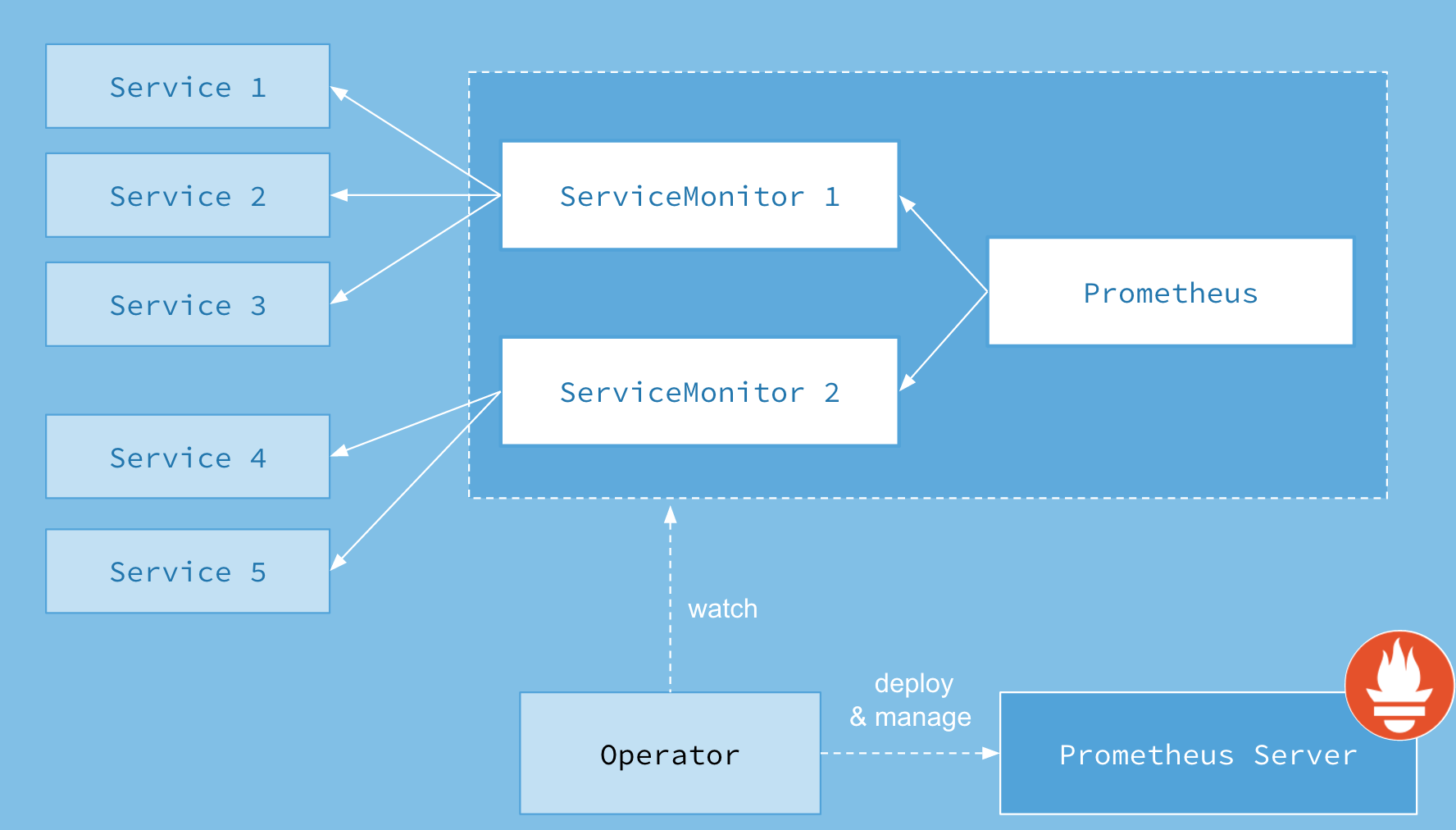
组件说明:
Prometheus:声明式创建和管理Prometheus Server实例
Prometheus Server: Operator 根据自定义资源 Prometheus 类型中定义的内容而部署的 Prometheus Server 集群
Operator: 创建Prometheus、PodMonitor、ServiceMonitor、AlertManager以及PrometheusRule这5个CRD资源对象,并一直监控和维持它们状态
ServiceMonitor: 该资源描述了Prometheus Server的target列表,Operator会监听该资源的变化来动态更新Prometheus Server的scrape target,
通过Selector来选择labels让Prometheus Server拉取Node Server的metrics数据
helm 部署Prometheus-Operator
添加azure的helm仓库
helm repo add azure http://mirror.azure.cn/kubernetes/charts/
下载chart并部署
helm pull azure/prometheus-operator
kubectl create ns monitor
注意:因为helm3废弃了crd-install hooks,所以要先部署crds目录下的yaml并禁用helm chart里面的createCustomResource
kubectl apply -f crds/
helm install prometheus -n monitor .
一杯咖啡时间,查看部署状态:kubectl get all -n monitor
kubectl get all -n monitor
NAME READY STATUS RESTARTS AGE
pod/alertmanager-prometheus-prometheus-oper-alertmanager-0 2/2 Running 0 27m
pod/prometheus-grafana-966c5cdf8-lh2vp 2/2 Running 0 29m
pod/prometheus-kube-state-metrics-6d6fc7946-fkh47 1/1 Running 0 29m
pod/prometheus-prometheus-node-exporter-bkvwx 1/1 Running 0 29m
pod/prometheus-prometheus-node-exporter-flc5d 1/1 Running 0 29m
pod/prometheus-prometheus-node-exporter-tgjvg 1/1 Running 0 29m
pod/prometheus-prometheus-node-exporter-w2hlw 1/1 Running 0 29m
pod/prometheus-prometheus-oper-operator-85cbf9df6b-kh2qx 2/2 Running 0 29m
pod/prometheus-prometheus-prometheus-oper-prometheus-0 3/3 Running 0 27m
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
service/alertmanager-operated ClusterIP None <none> 9093/TCP,9094/TCP,9094/UDP 27m
service/prometheus-grafana ClusterIP 172.17.224.223 <none> 80/TCP 29m
service/prometheus-kube-state-metrics ClusterIP 172.17.116.249 <none> 8080/TCP 29m
service/prometheus-operated ClusterIP None <none> 9090/TCP 27m
service/prometheus-prometheus-node-exporter ClusterIP 172.17.114.168 <none> 9100/TCP 29m
service/prometheus-prometheus-oper-alertmanager ClusterIP 172.17.95.147 <none> 9093/TCP 29m
service/prometheus-prometheus-oper-operator ClusterIP 172.17.103.56 <none> 8080/TCP,443/TCP 29m
service/prometheus-prometheus-oper-prometheus ClusterIP 172.17.27.18 <none> 9090/TCP 29m
NAME DESIRED CURRENT READY UP-TO-DATE AVAILABLE NODE SELECTOR AGE
daemonset.apps/prometheus-prometheus-node-exporter 4 4 4 4 4 <none> 29m
NAME READY UP-TO-DATE AVAILABLE AGE
deployment.apps/prometheus-grafana 1/1 1 1 29m
deployment.apps/prometheus-kube-state-metrics 1/1 1 1 29m
deployment.apps/prometheus-prometheus-oper-operator 1/1 1 1 29m
NAME DESIRED CURRENT READY AGE
replicaset.apps/prometheus-grafana-966c5cdf8 1 1 1 29m
replicaset.apps/prometheus-kube-state-metrics-6d6fc7946 1 1 1 29m
replicaset.apps/prometheus-prometheus-oper-operator-85cbf9df6b 1 1 1 29m
NAME READY AGE
statefulset.apps/alertmanager-prometheus-prometheus-oper-alertmanager 1/1 27m
statefulset.apps/prometheus-prometheus-prometheus-oper-prometheus 1/1 27m
部署grafana和Prometheus的ingress
grafana-ingress.yaml
apiVersion: extensions/v1beta1
kind: Ingress
metadata:
name: grafana-ingress
namespace: monitor
spec:
rules:
- host: grafana.joey.com
http:
paths:
- backend:
serviceName: prometheus-grafana
servicePort: 80
prometheus.yaml
apiVersion: extensions/v1beta1
kind: Ingress
metadata:
name: prometheus-ingress
namespace: monitor
spec:
rules:
- host: prometheus.joey.com
http:
paths:
- backend:
serviceName: prometheus-prometheus-oper-prometheus
servicePort: 9090
应用yaml并修改本地hosts记录表(C:\Windows\System32\drivers\etc),此时浏览器输入域名即可访问对应服务,至此,服务部署完成
实践操作
配置监控服务
创建一个服务并使用operator配置监控:
kind: Service
apiVersion: v1
metadata:
name: spring-base-service
labels:
app: springboot-service
spec:
selector:
app: base-service
ports:
- name: web
port: 8080
---
apiVersion: extensions/v1beta1
kind: Deployment
metadata:
name: tomcat-base-service
spec:
replicas: 2
template:
metadata:
labels:
app: base-service
spec:
containers:
- name: base-service
image: test/tomcat:v1
ports:
- name: web
containerPort: 8080
---
apiVersion: monitoring.coreos.com/v1
kind: ServiceMonitor
metadata:
name: java-service-monitor
namespace: monitoring
labels:
app: springboot
spec:
namespaceSelector:
matchNames:
- default
selector:
matchLabels:
app: springboot-service
endpoints:
- port: web
---
apiVersion: monitoring.coreos.com/v1
kind: Prometheus
metadata:
name: pro-java
namespace: monitoring
spec:
serviceAccountName: prometheus
serviceMonitorSelector:
matchLabels:
app: springboot
app: tomcat
ruleSelector:
matchLabels:
prometheus: javaapp
alerting:
alertmanagers:
- name: alertmanager-example
namespace: monitoring
port: web
resources:
requests:
memory: 400Mi
工作流程:
1:创建一个名字为pro-java的**prometheus**,该对象选择标签为**app: springboot**和app: tomcat的**ServiceMonitor**,也选择规则标签为**prometheus: javaapp**的**PrometheusRule**
2:创建一个名字为java-service-monitor的ServiceMonitor,该对象选择标签为**app: springboot**的**service**,service选择标签为**app: base-service**的**deployment**
若希望ServiceMonitor可以关联任意ns下的标签:
spec:
namespaceSelector:
any: true
手动监控
默认情况node_exporter监控在9100端口
监控主机
node_exporter通过采集器决定采集或暴露哪些资源供Prometheus采集
textfile收集器:自定义暴漏指标,这些自定指标可能时批处理或cron作业等无法抓取的,可能没有export源
创建目录保存文件:mkdir /data/pro/exporter/textfile/ 文件名称后缀为metricsName.Prom,文件名必须为.prom结尾
创建文件信息(格式):metadataName{labelKey:"labelValue"}value
格式说明:
metadata: 指标名称
label: 标签名称
value: 指标值
example: container_cpu_free{area="bj"}60
1: 提供上下文
启动(可用--no来修改采集器状态,比如--no-collector.arp):node_exporter --collector.textfile.directory /data/pro/exporter/textfile
systemd收集器:记录systemd中的服务和系统状态
采集systemd管理的部分内容,需要将特定服务加入白名单:node_exporter --collector.systemd.unit-whitelist="(docker|ssh|rsyslog).service"
过滤收集器
使用params块中的collect[]列表指定,然后作为URL参数传递给抓取请求
scrape_configs:
- job_name: 'node'
static_configs:
- tatgets: ['192.168.10.13:9100']
params:
collect[]:
- cpu
- meminfo
- diskstats
- netstat
- filesystem
- systemd
例如:curl -g -X GET http://192.168.10.13:9100/metrics?collect[]=cpu
监控docker
Google的cAdvisor工具,单个cAdvisor容器返回针对docker守护进程和所在运行容器的指标,Prometheus通过它导出指标并存储到其他如kafka,es等系统
运行cAdvisor
docker run -itd --name cadvisor --volume=/:/rootfs:ro --volume=/var/run:/var/run:rw --volume=/sys:/sys:ro --volume=/var/lib/docker/:/var/lib/docker:ro -p 8080:8080 google/cadvisor
查看相关信息
查看cadvisor web界面:192.168.10.13:8080/containers 查看metrics信息:192.168.10.13:8080/metrics
配置prometheus
scrape_configs:
- job_name: 'docker'
static_configs:
- tatgets: ['192.168.10.13:8080']
指标及标签操作
通过目标配置的标签来发现并采集节点资源,其中包含一组称为元数据的标签,以_meta_为前缀,也可根据目标配置来设置其他标签,如 scheme(http/https),address(目标地址),metrics_path(指标具体路径))
1: 配置标签会在抓取的生命周期中重复利用以生成其他标签,如 instance标签的默认内容是_address_标签的内容
2: 每个标签有一个默认值,如_metrics_path_默认为/metrics,_scheme_默认为http,若路径中含有URL参数,则前缀设置为_param_*
3: 有时未看到带有_前缀和后缀的标签是因为这些标签在生命周期的后期被删除了,或被排除掉不显示
4:目标列表和标签返回给Prometheus时,其中有一些标签可以被覆盖,例如:
scrape_configs:
- job_name: 'node'
scheme: https
metrics_path:/newmetrics
static_configs:
- tatgets: ['192.168.10.13:9100']
字段说明:
将scheme覆盖为https,将metrics_path覆盖为newmetrics
5:Prometheus可以在数据抓取前对指标进行重新标记,并在抓取数据后再次重新标记存入服务器
服务发现 ---> 配置 ---> 重新标记(relable_configs) ---> 抓取 --> 重新标记(metrics_relable_configs)
标签
标签提供了时间序列的维度,可以定义目标并为时间序列提供上下文(更改或添加标签会重新创建新的时间序列)
拓扑标签:通过物理或逻辑组成来切割服务组件,如datacenter标签
每个指标自带两个拓扑标签:job(类型名称)和instance(IP和Port,来自_address_标签)
模式标签:比如url,error_code或user等
重新标记
由于环境复杂无法控制监控的所有资源以及所有暴露的监控数据,通过重新标记可以控制,管理并标准化环境中的指标
1:删除不必要的标签
2:从指标中删除敏感信息或不需要的标签
3:添加,编辑或修改指标的标签值或标签格式
举例说明:
- job_name: 'docker'
static_configs:
- targets: ['192.168.10.13']
metrics_relabel_configs:
- source_labels: [_name]
spearator: ',')
regex: '(container_task_state|container_memory_failures_total)'
action: drop
参数解释:
1: 使用source_labels参数选择要操作的指标,多个标签通过";"进行连接,也可以使用separator参数覆盖分隔符配置(自定义分隔符spearator: ',')
2: 该job捕获两个指标(container_task_state和container_memory_failures_total),如果指定了多个源标签,使用分隔符分开每个正则(regex1;regex2)
3: 该指标包含大量时间序列,仅保留有价值数据,在存储之前使用drop操作删除指标
替换标签值
在cadvisor指标中都有一个id标签,例如: id="/docker/6sakjndjsa4312hjqwajsnda231sndaksdja431y8ausdsanda231",只获取容器id,则进行如下操作:
metrics_relabel_configs:
- source_labels: [id]
regex: '/docker/([a-z0-9]+);'
replacement: $1
target_label: container_id
此处没有设置action,是因为默认为replace操作,若覆盖并添加已存在的标签时honor_labels会控制冲突并通过添加exported前缀来重命名现有标签(默认为false)
删除标签
通常用来隐藏敏感信息或简化时间序列
metric_relabel_configs:
- regex: 'kernelVersion'
action: labeldrop
删除正则表达式所匹配的所有标签,labelkeep为保留标签删除其他不匹配标签
使用USE方法监控
CPU 指标
CPU使用率:node_cpu_seconds_total(按模式细分并按使用的时间进行显示)
计算每种CPU模式的每秒使用率:irate(node_cpu_seconds_total{job="node-exporter"}[5m])
聚合不同CPU和模式间的指标:avg(irate(node_cpu_seconds_total{job="node-exporter"}[5m]))by(instance)
五分钟内CPU使用率百分比:100-avg(irate(node_cpu_seconds_total{job="node-exporter",mode="idle"}[5m]))by(instance)*100
irate: 用于计算范围向量中时间序列增加的每秒即时速率
CPU饱和度: node_load(查看主机时间范围内的平均负载),平均负载少于CPU的数量通常时正常,长时间超过表示CPU饱和*
计算主机上CPU数量:count by (instance)(node_cpu_seconds_total{mode=“idle”})
内存
内存使用率:所有指标都是字节单位表示
node_memory_MemTotal_bytes: 主机上的总内存
node_memory_MemFree_bytes: 主机上可用内存
node_memory_Buffers_bytes: 缓冲缓存中的内存
node_memory_Cached_bytes: 页面缓存中的内存
内存使用率:(node_memory_MemTotal_bytes-(node_memory_MemFree_bytes + node_memory_Buffers_bytes + node_memory_Cached_bytes))/node_memory_MemTotal_bytes*100
此时没有用by是应为u这些指标具有相同的维度
内存饱和度:通过检查内存和磁盘的读写来监控内存饱和度
node_vmstat_pswpin: 系统每秒从磁盘读到内存的字节数
node_vmstat_pswpout: 系统每秒从内存写到磁盘的字节数
对每个指标计算一分钟的速率,将两个速率相加乘以1024获得字节数: 1024 * sum by (instance) ((rate(node_vmstat_pgpgin[1m])+rate(node_vmstat_pgpgout[1m])))
磁盘
磁盘使用率:node_filesystem_size_bytes(显示被监控的每个文件系统挂载的大小)
计算根文件系统的使用率: (node_filesystem_size_bytes{mountpoint="/"} - node_filesystem_free_bytes {mountpoint="/"})/node_filesystem_free_bytes {mountpoint="/"}*100
可用正则匹配多个挂载点:mountpoint=~"/|/run"
计算增长速度来确定何时耗尽磁盘: 使用predict_linear函数
按照一小时内的增长速度来计算根目录4小时内耗尽的主机: predict_linear(node_filesystem_free_bytes {mountpoint="/"}[1h],4*3600)<0
按照一小时的增长速度来计算指定job主机上4小时内耗尽的目录: predict_linear(node_filesystem_free_bytes {job="node-exporter"}[1h],400*3600) <0
监控服务状态
使用systemd采集器的数据: node_systemd_unit_state指标暴露
查询主机上docker-service状态: node_systemd_unit_state{name="docker.service",state="active} 或者 node_systemd_unit_state{name="docker.service",state="active"}
up指标监控:实例健康则设置为1,数据抓取成功返回,抓取失败则设置为0(指标使用job和instance进行标记)
例如通过up指标可以获取到当前所有运行的Exporter实例以及其状态:
up{instance="localhost:8080",job="cadvisor"} 1
up{instance="localhost:9090",job="prometheus"} 1
up{instance="localhost:9100",job="node"} 1
metadata指标: 提供资源的上下文信息 查询某地区数据:medata{datacenter = “BJ”}
使用metadata指标进行向量匹配:左侧向量中的每个元素在右侧向量中查找对应的匹配元素(一对一,一对多,多对一)
一对一匹配(从每一侧找到唯一匹配的条目对,on修饰只返回metadata指标的job和instance标签):node_systemd_unit_state{name="docker.service"} == 1 and on (instance,job) metadata{datacenter="BJ"}
多对一和一对多匹配:其中一侧向量中的元素与另外一侧向量中的多个元素相匹配(用group_left或group_right修饰显式指定): method_code:http_errors:rate5m / ignoring(code) group_left method:http_requests:rate5m
说明:左向量method_code:http_errors:rate5m包含两个标签method和code,而右向量method:http_requests:rate5m中只包含一个标签method,因此匹配时需要使用ignoring限定匹配的标签为code,在限定匹配标签后,右向量中的元素可能匹配到多个左向量中的元素 因此该表达式的匹配模式为多对一,需要使用group修饰符group_left指定左向量具有更好的基数
自动监控
通过使用服务发现来检测,分类和识别新的和变更的目标
实现机制:1:从配置管理工具生成的文件中接受目标列表 2:查询API获取目标列表 3:使用DNS记录以返回目标列表
发现方案:1: 基于文件的方式 2:基于云的方式 3:基于DNS的方式
基于文件:定期从指定文件中获取列表(通常由ansible等配置管理工具生成)
示例说明:
- job_name: node
file_sd_configs:
- files:
- targets/nodes/*.json
refresh_interval: 5m
mkdir /etc/prometheus/targets/{nodes,docker},创建两个json文件来保存节点列表和docker守护进程列表
创建node.json文件并写入列表:
[{
"targets": [
"192.168.10.13:9100",
"192.168.10.14:9100"
]
}]
创建daemon文件并写入列表:
[{
"targets": [
"192.168.10.13:8080",
"192.168.10.14:8080"
],
"labels": {
"datacenter": "BJ"
}
}]
细节说明:
1:若现有静态配置也会将其移动到所创建的文件列表中
2:由于配置了标签会在重新标记阶段自动给每个目标添加一个元数据标签_meta_filepath,包含配置目标的文件路径和文件名
基于API的服务发现
使用工具和平台现有的数据存储或API来返回目标列表: 例如consul,kubernetes
consul使用其自带的API接口自动向其注册服务,Prometheus 一直监视(watch)consul服务,当发现consul中符合要求的服务有新变化时更新Prometheus监控对象
- job_name: 'consul'
consul_sd_configs:
- server: 'server:8500'
relabel_configs:
- source_labels: [__meta_consul_tags]
regex: .*,prome,.*
action: keep
- source_labels: [__meta_consul_service]
target_label: job
kubernetes使用daemonset控制器在集群中的每个节点上自动部署pod,DaenonSet使用toleration确保pod在所有节点上运行
节点亲和性:
Pod 间亲和通过 PodSpec 中 affinity 字段下的 podAffinity 字段进行指定
requiredDuringSchedulingIgnoredDuringExecution:必须满足条件才调度
preferredDuringSchedulingIgnoredDuringExecution:满足条件进行尝试性的调度
IgnoredDuringExecution:若标签发生变化不符合亲和性规则后原来的pod仍然继续运行(亲和性只在调度期间生效)
举例说明:
apiVersion: v1
kind: Pod
metadata:
name: with-node-affinity
spec:
affinity:
nodeAffinity:
requiredDuringSchedulingIgnoredDuringExecution:
nodeSelectorTerms:
- matchExpressions:
- key: kubernetes.io/nodetype
operator: In
values:
- storage
- database
preferredDuringSchedulingIgnoredDuringExecution:
- weight: 1
preference:
matchExpressions:
- key: another-node-label-key
operator: In
values:
- another-node-label-value
containers:
- name: with-node-affinity
image: k8s.gcr.io/pause:2.0
字段说明:
1:该规则表示pod只运行在节点具有kubernetes.io/nodetype的标签键且标签值为storage或database的节点上,在满足此条件的节点中优先调度到具有标签键为 another-node-label-key 且标签值为 another-node-label-value 的节点
2:节点亲和语法支持下面的操作符: In,NotIn,Exists,DoesNotExist,Gt,Lt,你可以使用 NotIn 和 DoesNotExist 来实现节点反亲和行为,或者使用节点污点将 pod 从特定节点中驱逐
3: preferredDuringSchedulingIgnoredDuringExecution中的 weight 字段值的范围是 1-100
注意事项:
(1) 同时指定了 nodeSelector 和 nodeAffinity,两者必须都要满足,才能将 pod 调度到候选节点上
(2) 指定了多个与 nodeAffinity 类型关联的 nodeSelectorTerms,则如果其中一个 nodeSelectorTerms 满足的话,pod将可以调度到节点上
(3) 指定了多个与 nodeSelectorTerms 关联的 matchExpressions,则只有当所有 matchExpressions 满足的话,pod 才会可以调度到节点上
节点反亲和性
pod 间亲和与反亲和可用根据已经允许在节点上的pod的标签来约束pod的调度(不是基于节点的标签),pod 间反亲和通过 PodSpec 中 affinity 字段下的 podAntiAffinity 字段进行指定
apiVersion: v1
kind: Pod
metadata:
name: with-pod-affinity
spec:
affinity:
podAffinity:
requiredDuringSchedulingIgnoredDuringExecution:
- labelSelector:
matchExpressions:
- key: security
operator: In
values:
- storage
topologyKey: failure-domain.beta.kubernetes.io/zone
podAntiAffinity:
preferredDuringSchedulingIgnoredDuringExecution:
- weight: 100
podAffinityTerm:
labelSelector:
matchExpressions:
- key: security
operator: In
values:
- database
topologyKey: failure-domain.beta.kubernetes.io/zone
containers:
- name: with-pod-affinity
image: k8s.gcr.io/pause:2.0
解释说明:
1:在这个pod的affinity 配置定义了一条 pod 亲和规则和一条 pod 反亲和规则, podAffinity 配置为 requiredDuringSchedulingIgnoredDuringExecution,podAntiAffinity 配置为 preferredDuringSchedulingIgnoredDuringExecution
2:pod 亲和规则表示,仅当节点和至少一个已运行且有键为“security”且值为“storage”的标签的 pod 处于同一节点时,才可以将该 pod 调度到节点上
3:pod 反亲和规则表示,如果节点已经运行了一个具有键“security”和值“database”的标签的 pod,则该 pod 不希望将其调度到该节点上
自动发现配置
prometheus配置文件分析
/etc/prometheus/config_out/prometheus.env.yaml
截取部分片段分析:
global:
evaluation_interval: 30s
scrape_interval: 30s
external_labels:
prometheus: monitor/prometheus-prometheus-oper-prometheus
prometheus_replica: prometheus-prometheus-prometheus-oper-prometheus-0
rule_files:
- /etc/prometheus/rules/prometheus-prometheus-prometheus-oper-prometheus-rulefiles-0/*.yaml
scrape_configs:
- job_name: monitor/prometheus-prometheus-oper-alertmanager/0
honor_labels: false
kubernetes_sd_configs:
- role: endpoints
namespaces:
names:
- monitor
metrics_path: /metrics
relabel_configs:
- action: keep
source_labels:
- __meta_kubernetes_service_label_app
regex: prometheus-operator-alertmanager
- action: keep
- job_name: monitor/prometheus-prometheus-oper-kube-controller-manager/0
honor_labels: false
kubernetes_sd_configs:
- role: endpoints
namespaces:
names:
- kube-system
bearer_token_file: /var/run/secrets/kubernetes.io/serviceaccount/token
relabel_configs:
- action: keep
source_labels:
- __meta_kubernetes_service_label_app
regex: prometheus-operator-kube-controller-manager
- action: keep
source_labels:
- __meta_kubernetes_service_label_release
regex: prometheus
- action: keep
source_labels:
- __meta_kubernetes_endpoint_port_name
regex: http-metrics
- source_labels:
- __meta_kubernetes_endpoint_address_target_kind
- __meta_kubernetes_endpoint_address_target_name
separator: ;
regex: Node;(.*)
replacement: ${1}
target_label: node
- source_labels:
- __meta_kubernetes_endpoint_address_target_kind
- __meta_kubernetes_endpoint_address_target_name
separator: ;
regex: Pod;(.*)
replacement: ${1}
target_label: pod
- source_labels:
- __meta_kubernetes_namespace
target_label: namespace
- source_labels:
- __meta_kubernetes_service_name
target_label: service
- source_labels:
- __meta_kubernetes_pod_name
target_label: pod
- source_labels:
- __meta_kubernetes_service_name
target_label: job
replacement: ${1}
- source_labels:
- __meta_kubernetes_service_label_jobLabel
target_label: job
regex: (.+)
replacement: ${1}
- target_label: endpoint
replacement: http-metrics
alerting:
alert_relabel_configs:
- action: labeldrop
regex: prometheus_replica
alertmanagers:
- path_prefix: /
scheme: http
kubernetes_sd_configs:
- role: endpoints
namespaces:
names:
- monitor
api_version: v2
relabel_configs:
- action: keep
source_labels:
- __meta_kubernetes_service_name
regex: prometheus-prometheus-oper-alertmanager
- action: keep
source_labels:
- __meta_kubernetes_endpoint_port_name
regex: web
可见整个yaml配置文件分为四个模块:
global: 服务全局配置
evaluation_interval:prometheus评估规则的频率(记录规则:允许预先计算使用频繁且开销大的表达式,并将结果保存为一个新的时间序列数据 警报规则:允许定义报警条件)
scrape_interval:应用程序或服务抓取数据的时间间隔
external_labels:外部标签,会添加到拉取的数据并存到数据库中
rule_files: 用来指定包含记录规则或警报规则的文件列表
scrape_configs: 用来指定Prometheus抓取的所有目标,该目标包含标签,身份验证等必须信息
job_name:任务名称
honor_labels: 用于解决拉取数据标签有冲突,当设置为 true, 以拉取数据为准,否则以服务配置为准
metrics_path: 拉取节点的 metric 路径
scheme: 拉取数据访问协议
relabel_configs: 拉取数据重置标签配置
kubernetes_sd_configs: kubernetes服务发现,向kubernetesAPI查询符合特定搜索条件的目标
repalce/labelmap/labelkeep/labeldrop:对Target标签进行过滤,仅保留符合过滤条件的标签
repalce:允许用户根据Target的Metadata标签重写或者写入新的标签键值对
labelmap:根据regex的定义去匹配Target实例所有标签的名称,并且以匹配到的内容为新的标签名称,其值作为新标签的值
labelkeep: 移除那些不匹配regex定义的所有标签
labeldrop:符合regex规则的标签从Target实例中移除
alerting: 用来设置Prometheus的警报
alert_relabel_configs: 动态修改 alert 属性的规则配置
alertmanagers: 用于动态发现 Alertmanager 的配置
基于DNS的服务发现
DNS服务发现允许你指定DNS条目列表,然后查询这些条路中的记录以发现目标列表,依赖于A,AAAA或SRV DNS记录查询
- job_name: webapp
dns_sd_configs:
- names: ['_prometheus._tcp.example.com']
当Prometheus查询目标时,他会通过DNS服务器查询example.com域,然后搜索名为_prometheus._tcp.example.com的SRV记录
SRV记录示例:_service._proto_name. TTL IN SRV priority weight port target .
_prometheus._tcp.example.com 300 INSRV10 1 9100 webapp1.example.com
_prometheus._tcp.example.com 300 INSRV10 1 9100 webapp2.example.com
字段说明:
_service:要查询的服务名称
_proto: 服务协议,通常是TCP或UDP
IN:标准DNS类
priority:目标主机优先级
weight: 控制具有相同优先级的目标偏好
port和target: 服务运行的钝口和提供服务的主机的主机名
使用DNS服务发现来查询单个A或AAAA记录:
- job_name: webapp
dns_sd_configs:
- names: ['example.com']
type: A
port: 9100
细节说明:
1: A和AAAA只返回主机,所以要加上查询类型和端口
2: DNS 服务发现只有一个元数据标签_meta_dns_name,它被设置为生成目标的特定DNS记录
查询后会返回webapp1.example.com,webapp2.example.com两个目标
探针监控
Prometheus通过运行Blackbox_exporter来进行探测,该export会探测远程目标并暴露在本地端点上收集的任何时间序列
Blackbox exporter是go写的二进制程序,允许通过HTTP,HTTPS,DNS,TCP和ICMP来探测端点,点击下载部署
wget https://github.com/prometheus/blackbox_exporter/releases/download/v0.16.0/blackbox_exporter-0.16.0.linux-amd64.tar.gz
tar -xf blackbox_exporter-0.16.0.linux-amd64.tar.gz && cp -ra blackbox_exporter-0.16.0.linux-amd64/blackbox_exporter /usr/local/bin/
mkdir /etc/blackbox &&cp -ra blackbox_exporter-0.16.0.linux-amd64/blackbox.yml /etc/blackbox
介绍说明:
1:exporter通过yaml的配置文件进行配置,并使用命令行参数指定
2:exporter使用模块来定义各种检查,每个模块都有一个名称和特定指针
配置探针的配置
详细配置说明:
prober: 探针类型,,http https tcp dns icmp
timeout: 超时时间,单位默认秒
http/tcp.dns/icmp等: 探针详细配置
valid_http_versions: 检查http的版本号
valid_status_codes: 检查http的状态码
method: 使用什么HTTP方法检查
headers: 为探针设置HTTP header
no_follow_redirects: 探针是否将遵循任何重定向,默认false
fail_if_ssl: 如果存在SSL,则探测失败
fail_if_not_ssl: 如果不存在SSL,则探测失败
fail_if_body_matches_regexp: 如果响应主体与正则表达式匹配,则探测失败
fail_if_body_not_matches_regexp: 如果响应主体与正则表达式不匹配,则探测失败
fail_if_header_matches: 如果响应头与正则表达式匹配,则探测失败,对于具有多个值的header,如果*至少一个*匹配,则失败
fail_if_header_not_matches: 如果响应头与正则表达式不匹配,则探测失败,对于具有多个值的header,如果* none *不匹配,则失败
tls_config: HTTP探针的TLS协议的配置
http_basic_auth: 目标的HTTP基本身份验证凭据
http_custom_ca: 目标ca证书验证
更多参数参考官方文档
modules:
http_2xx_check:
prober: http
timeout: 5s
http:
valid_http_versions: ["HTTP/1.1", "HTTP/2"]
valid_status_codes: ['200','304']
method: GET
headers:
Host: vhost.example.com
Accept-Language: en-US
Origin: example.com
no_follow_redirects: false
fail_if_ssl: false
fail_if_not_ssl: false
fail_if_body_matches_regexp:
- "Could not connect to database"
fail_if_body_not_matches_regexp:
- "Download the latest version here"
fail_if_header_matches: # Verifies that no cookies are set
- header: Set-Cookie
allow_missing: true
regexp: '.*'
fail_if_header_not_matches:
- header: Access-Control-Allow-Origin
regexp: '(\*|example\.com)'
tls_config:
insecure_skip_verify: false
preferred_ip_protocol: "ip4" # defaults to "ip6"
ip_protocol_fallback: false # no fallback to "ip6"
http_post_2xx:
prober: http
timeout: 5s
http:
method: POST
headers:
Content-Type: application/json
body: '{}'
http_basic_auth:
prober: http
timeout: 5s
http:
method: POST
headers:
Host: "login.example.com"
basic_auth:
username: "username"
password: "mysecret"
http_custom_ca:
prober: http
http:
method: GET
tls_config:
ca_file: "/certs/my_cert.crt"
tls_connect:
prober: tcp
timeout: 5s
tcp:
tls: true
tcp_connect:
prober: tcp
timeout: 5s
imap_starttls:
prober: tcp
timeout: 5s
tcp:
query_response:
- expect: "OK.*STARTTLS"
- send: ". STARTTLS"
- expect: "OK"
- starttls: true
- send: ". capability"
- expect: "CAPABILITY IMAP4rev1"
smtp_starttls:
prober: tcp
timeout: 5s
tcp:
query_response:
- expect: "^220 ([^ ]+) ESMTP (.+)$"
- send: "EHLO prober"
- expect: "^250-STARTTLS"
- send: "STARTTLS"
- expect: "^220"
- starttls: true
- send: "EHLO prober"
- expect: "^250-AUTH"
- send: "QUIT"
irc_banner_example:
prober: tcp
timeout: 5s
tcp:
query_response:
- send: "NICK prober"
- send: "USER prober prober prober :prober"
- expect: "PING :([^ ]+)"
send: "PONG ${1}"
- expect: "^:[^ ]+ 001"
icmp_example:
prober: icmp
timeout: 5s
icmp:
preferred_ip_protocol: "ip4"
source_ip_address: "192.168.10.13"
dns_udp_example:
prober: dns
timeout: 5s
dns:
query_name: "www.prometheus.io"
query_type: "A"
valid_rcodes:
- NOERROR
validate_answer_rrs:
fail_if_matches_regexp:
- ".*127.0.0.1"
fail_if_all_match_regexp:
- ".*127.0.0.1"
fail_if_not_matches_regexp:
- "www.prometheus.io.\t300\tIN\tA\t127.0.0.1"
fail_if_none_matches_regexp:
- "127.0.0.1"
validate_authority_rrs:
fail_if_matches_regexp:
- ".*127.0.0.1"
validate_additional_rrs:
fail_if_matches_regexp:
- ".*127.0.0.1"
dns_soa:
prober: dns
dns:
query_name: "prometheus.io"
query_type: "SOA"
dns_tcp_example:
prober: dns
dns:
transport_protocol: "tcp" # defaults to "udp"
preferred_ip_protocol: "ip4" # defaults to "ip6"
query_name: "www.prometheus.io"
你需要哪个模块跟着格式写就可以
创建prometheus来抓取上面配置的指标
例如创建http_probe的job来查询http_2xx_check模块
- job_name: 'http_probe'
metrics_path: /probe
params:
moudle: [http_2xx_check]
file_sd_configs:
- files:
- 'targets/probes/http_probes.json'
refresh_interval: 5m
relabel_configs:
- source_labels: [_address_]
target_label: _param_target
- source_labels: [_param_target]
target_label: instance
- target_label: _address_
replacement: 192.168.10.13:9115
创建json文件:
[{
"targers": [
"http://www.baidu.com",
"https://www.podsbook.com",
""
]
}]
细节说明:
1:监控HTTP和HTTPS两种协议
2:Prometheus如何找到exporter?
(1) 第一个重新标记将_address_标签(targets的地址)写入_param_target标签来创建参数
(2) 第二个重新标记将_param_target标签写入instance标签
(3) 使用exporter的主机名来重新标记_address_标签
3:replacement:black-exporter所在的机器和端口
重新标记会为抓取构造如下URL: http://192.168.10.13:9115/probe?target=www.baidu.com?moudle=http_2xx_check
未完待续