Joey Xu
Thursday, September 1, 2022
cilium中的datapth简解
cilium收发包是极其复杂的过程,本节将介绍数据包是如何穿过 network datapath(网络数据路径)的:包括从硬件到内核,再到用户空间
本文中只讨论收包的过程,涉及到的知识点比较多,望君耐心看完,多读几遍,定会颇有收获
网卡驱动
驱动:网卡需要有驱动才能工作,驱动是加载到内核中的模块,负责衔接网卡和内核的网络模块,驱动在加载的时候将自己注册进网络模块,当相应的网卡收到数据包时,网络模块会调用相应的驱动程序处理数据
模块:是在内核空间运行的程序,实际上是一种目标对象文件,没有链接,不能独立运行,但可以装载到系统中作为内核一部分运行,从而动态扩充内核的功能 Linux下对于一个硬件的驱动,可以有两种方式: 1:直接加载到内核代码中,启动内核时就会驱动此硬件设备 2:以模块方式,编译生成一个.o文件,当应用程序需要时再加载进内核空间运行,比如执行命令:insmod SHT21.ko 网卡(NIC): 硬件,内核通过网卡驱动与网卡交互,网卡本身是有内存的,每个网卡一般都有4k以上的内存(fifo队列),用来发送、接受数据。 数据发送:数据从主内存搬到网卡之后,要先在网卡自身的内存中排队,再按先后顺序发送 数据接受:数据从以太网传递到网卡时,网卡也是先把数据存储到自身的内存中,每收到一帧数据,就经过中断,以DMA方式从网卡内存拷贝至内核内存
tap/tun设备
TUN与TAP是操作系统内核中的虚拟网络设备,操作系统通过TUN/TAP设备向绑定该设备的用户空间的程序发送数据,反之,用户空间的程序使用标准网络接口socket API操作tun/tap设备发送数据,它们都是从
/dev/net/tun字符设备进行读取数据(2.6+)1:Tun 是三层网络设备,从/dev/net/tun字符设备上读取的是IP数据包,写入的也只能是IP数据包,因此不能进行二层操作,如发送ARP请求和以太网广播 2:Tap 是二层网络设备,处理的是二层数据帧,从 /dev/net/tun 字符设备上读取的是数据帧,写入的也只能是数据帧 示例: # 创建 tap ip tuntap add dev tap0 mode tap # 创建 tun ip tuntap add dev tun0 mode tun # 删除 tap ip tuntap del dev tap0 mode tap # 删除 tun ip tuntap del dev tun0 mode tun数据发送流程:
+----------------------------------------------------------------+ | | | +--------------------+ +--------------------+ | | | User Application A | | User Application B |<-----+ | | +--------------------+ +--------------------+ | | | | 1 | 5 | | |...............|......................|...................|.....| | ↓ ↓ | | | +----------+ +----------+ | | | | socket A | | socket B | | | | +----------+ +----------+ | | | | 2 | 6 | | |.................|.................|......................|.....| | ↓ ↓ | | | +------------------------+ 4 | | | | Newwork Protocol Stack | | | | +------------------------+ | | | | 7 | 3 | | |................|...................|.....................|.....| | ↓ ↓ | | | +----------------+ +----------------+ | | | | eth0 | | tun0 | | | | +----------------+ +----------------+ | | | | | | | | | 8 +---------------------+ | | | | +----------------|-----------------------------------------------+ ↓ Physical Network数据包发送的整个流程为:
1: 用户层的应用程序 A 通过socket 将数据包发送给内核协议栈 2:内核协议栈查询路由表,发现数据包的下一跳地址应该为 TUN0 网卡,然后将数据包发送给虚拟网卡设备 TUN0 3:TUN0 接收到数据之后通过某种方式从内核空间将数据发送给运行在用户空间的应用程序 B 4:B收到数据包后进行一些处理,然后构造一个新的数据包,通过 socket 发送给内核协议栈 5:这个新的数据包的目的地址变成了一个外部地址,源地址变成了 eth0 的地址 6:内核协议栈查找路由表后无法找到目的地址,然后将数据包通过 eth0 网卡发送给网关,eth0 接收到数据之后将数据包发送到和 eth0 网卡物理相连的外部设备
描述符
描述符(Packet Descriptor)用来表达一个数据包在缓冲区内的
地址以及数据包在NIC中的状态(是否有异常发生)这是一个硬件相关的数据结构,由NIC去规定该结构的内容。描述符分成了接收描述符 (rx descriptor) 和传输描述符 (tx descriptor) ,接收描述符是一个用来描述网卡接收的数据缓冲区首地址和硬件用于存储包信息的数据结构
Ring Buffer
它是由NIC和驱动程序共享的一片区域,事实上,rx ring buffer存储的并不是实际的packet数据,而是一个
描述符,这个描述符指向了它真正的存储地址当有数据时,DMA负责从NIC取数据,并在Ring Buffer上按顺序找到下一个ready的Descriptor,将数据存入该Descriptor指向的sk_buff中,并标记槽为used,因为是按顺序找 ready 的槽,所以Ring Buffer是个FIFO的队列。 具体流程如下: 1:驱动程序启动时创建和初始化Ring Buffer,存储的是sk_buff缓冲区的描述符(物理地址和大小等),描述符中的缓冲区地址是DMA使用的物理地址 3:驱动通知网卡有一个新的描述符 4:网卡从rx ring buffer中取出描述符,从而获知sk_buff的地址和大小 5:网卡收到新的数据包 6:网卡将新数据包通过DMA直接写到sk_buff中 7:等sk_buff中的数据交由上层协议栈处理后,Ring Buffer中的描述更新为新分配的sk_buff sk_buff是linux内核网络代码中最重要的数据结构,用来表示已接收或将要传输的数据,它由许多变量组成,目标就是满足所有网络协议的需要,随着数据包在内核协议栈不同层次传递时,Linux 内核不是通过层与层之间的数据拷贝,而是通过增加协议头和移动指针来操作的。如果是从L4传输到L2,则是通过往sk_buff结构体中增加该层协议头来操作;如果是从L4到L2,则是通过移动sk_buff结构体中的data指针来实现,不会删除各层协议头
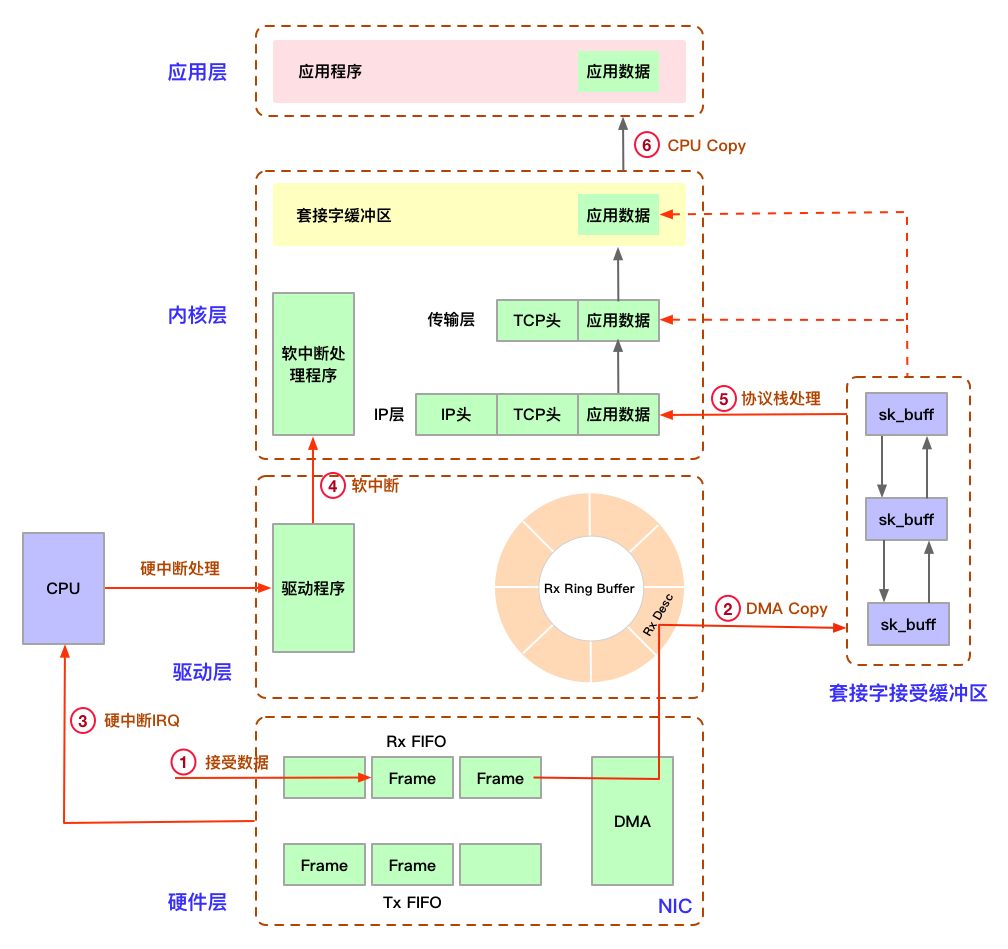
我们使用ifconfig命令可以看到
overruns和dropped两个字段,二者是对网络包接受过程的不同阶段的错误统计:overruns: 表示这个数据包还没有被进入到网卡的接收缓存fifo队列就被丢掉的错误数 比如说队列满了导致被丢掉,这部分丢包为rx_fifo_errors,在/proc/net/dev中体现为fifo字段增长。此时需要检查下cpu的负载及中断情况 dropped: 表示这个数据包已经进入到网卡的接收缓存fifo队列,从缓存队列拷贝至sk_buff中发生的错误数,由于系统原因被丢掉 比如说内存满了调整
ring buffer大小:# ethtool -g eth0 Ring parameters for eth0: Pre-set maximums: RX: 4096 RX Mini: 0 RX Jumbo: 0 TX: 4096 Current hardware settings: RX: 512 RX Mini: 0 RX Jumbo: 0 TX: 512 # ethtool -G eth0 rx 2048 tx 2048 Ring parameters for eth0: Pre-set maximums: RX: 4096 RX Mini: 0 RX Jumbo: 0 TX: 4096 Current hardware settings: RX: 2048 RX Mini: 0 RX Jumbo: 0 TX: 2048
Pre-se是预设的最大值,Current显示的当前值在修改时不能超过上面的最大值,否则会报错Cannot set device ring parameters: Invalid argument有些没法修改,得看你的实例支不支持,要不报错
Cannot set device ring parameters: Operation not supported
DMA
直接内存访问(Direct Memory Access): 外部设备
不通过CPU控制传输过程而直接与系统内存交换数据的接口技术DMA的数据传输过程分为几个部分: 1: 当外部设备有DMA使用需求时,会向DMAC控制器发出DMA请求信号(DREQ) 2: DMAC控制器接收到外部设备的请求信号后,会向CPU发出一个总线请求信号(HRQ) 3: CPU在接收到DMAC控制器发送过来的总线请求信号后,如果允许DMA传输,则会在总线空闲后,发出DMA响应信号(HLDA)。然后CPU会将控制总线、数据总线和地址总线置高阻态,即放弃对总线的控制权;另一方面,CPU会将有效的DMA响应信号发送给DMAC控制器,通知DMAC控制器CPU已经放弃了对总线的控制权 4: DMAC控制器收到总线发来的DMA响应信号(HLDA)后,会获得总线的控制权,并向外部设备发送应答信号DACK,通知外设可以进行DMA传输了 5: DMAC还会向存储器发送地址信号,向存储器和外设发出读/写控制信号,控制数据按设定的方向传输,实现外设与内存的数据传输 6: 数据全部传输结束后,DMAC向CPU发送HOLD信号,要求撤销DMAC控制器对总线的控制权,CPU收到该信号后,会使HLDA(DMA请求)信号无效,收回总线控制权DMA传输将数据从一个地址空间复制到另一个地址空间,提供在外设和存储器之间或者存储器和存储器之间的高速数据传输。当CPU初始化这个传输动作,传输动作本身是由DMA控制器来实现和完成的
DMA传输方式无需CPU直接控制传输,也没有中断处理方式那样保留现场和恢复现场过程,通过硬件为RAM和IO设备开辟一条直接传输数据的通道,使得CPU的效率大大提高
中断
是指处理器接收到来自硬体或软体的信号,提示发生了某个事件,应该被注意,这种情况就称为中断
中断分为硬中断和软中断: 硬中断(上半段): 由硬件自己生成,具有随机性,硬中断被CPU接收后,触发执行中断处理程序。中断处理程序只会处理关键性的、短时间内可以处理完的工作,剩余耗时较长工作,会放到中断之后,由软中断来完成。硬中断也被称为上半部分。 软中断(下半段): 由硬中断对应的中断处理程序生成,往往是预先在代码里实现好的,不具有随机性。(除此之外,也有应用程序触发的软中断)也被称为下半部分。
当NIC把数据包通过DMA复制到内核缓冲区
sk_buffer后,NIC立即发起一个硬件中断。CPU接收后,首先进入上半部分,网卡中断对应的中断处理程序是网卡驱动程序的一部分,之后由它发起软中断,进入下半部分,开始消费sk_buffer中的数据,交给内核协议栈处理.通过中断,能够快速及时地响应网卡数据请求,但如果数据量大,那么会产生大量中断请求,CPU大部分时间都忙于处理中断,效率很低。为了解决这个问题,现在的内核及驱动都采用一种叫
NAPI(new API)的方式进行数据处理,其原理可以简单理解为中断+轮询,在数据量大时,一次中断后通过轮询接收一定数量包再返回,避免产生多次中断.
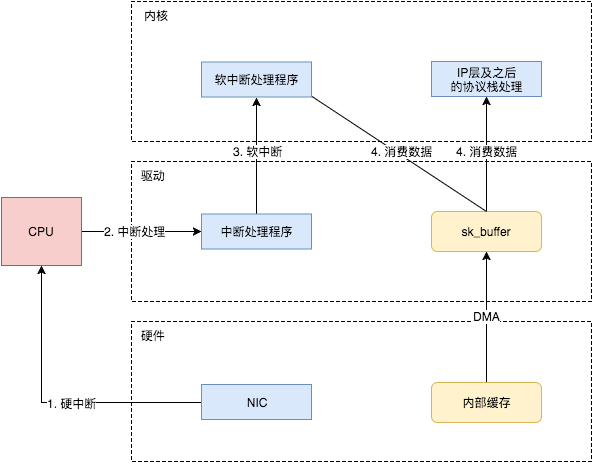
NAPI
NAPI 中断缓解技术,它是 Linux 上采用的一种
提高网络处理效率的技术。这是 Linux 内核中的一种通用抽象,任何等待不可抢占状态发生(wait for a preemptible state to occur)的模块,都可以使用这种注册回调函数的方式 .一般情况下,网卡接收到数据,通过硬中断通知CPU进行处理,当网卡有大量数据涌入时,每接收一
帧就产生一个中断,浪费大量网卡和cpu资源,所以系统采用了硬中断 + 软中断轮询(poll)技术,提升数据接收处理效率,因为硬件中断代价太高了,它们比系统上几乎所有东西的优先级都要高 .驱动注册的这个 poll 是一个
主动式 poll(active poll),执行 poll 方法的是运行在某个或者所有 CPU 上的内核线程(kernel thread),一旦执行就会持续处理 ,直到没有数据可供处理,然后进入 idle 状态,poll 会告诉网卡不要再触发硬件中断,使用软件中断(softirq)就行了。此后这些内核线程会轮询网卡的DMA区域来收包 .NAPI使用流程如下: 1: NAPI 被驱动 Enable,但是默认是关闭状态 2: 数据包到达 NIC 并且被 DMA 到 RAM(ring buffer) 中 3: NIC 产生 IRQ,触发了驱动中的 IRQ Handler 4: 驱动通过 softirq 唤醒 NAPI 子系统,通过使用驱动注册的 Poll 函数来获取数据包 5: 驱动关闭 NIC 的中断,这样可以通过驱动使用 NAPI 获取数据包而不用处理中断 6: 当所有数据包都已被处理,NAPI 被 disable,IRQs 被 re-enable 7: 当再次有数据包到达,重复步骤2首先,NAPI poll 机制不断调用驱动实现的 poll 方法,后者处理 RX 队列内的包,并最终将包送到正确的程序。如后面详细流程图
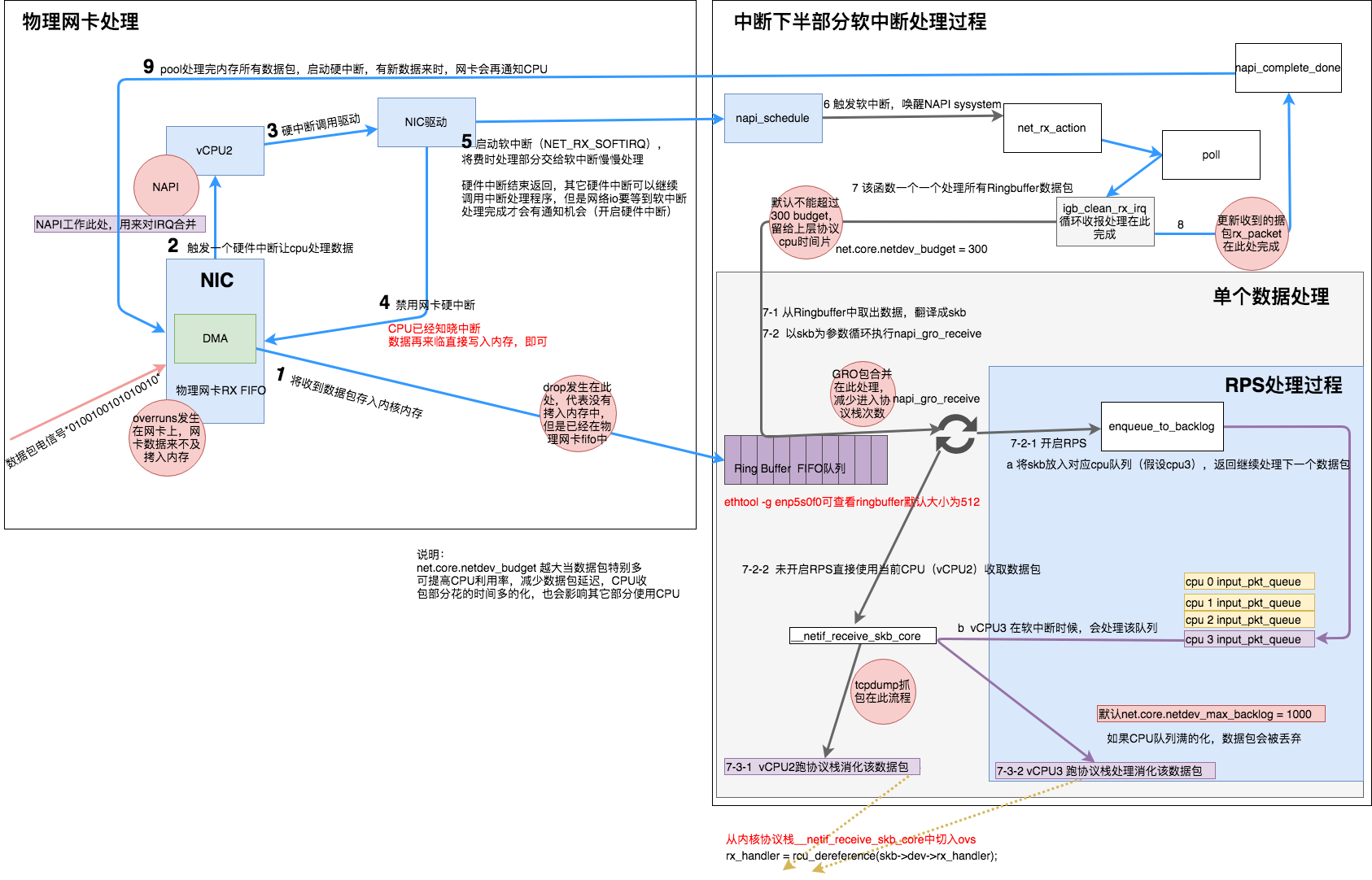
网卡工作流程
设备与驱动程序的数据处理是发生在二层的,所以上面多次提到网卡收到的是数据帧,接下来我们再看下它具体的工作流程
详细步骤如下:
skb: struct sk_buffer的简写1: 网卡收到数据包,先将高低电平转换到网卡fifo存储,网卡申请ring buffer中的描述,根据描述找到具体的物理地址,从fifo队列物理网卡会使用DMA将数据包写到了该物理地址,,其实就是skb_buffer中. 2: 这个时候数据包已经被转移到skb_buffer中,因为是DMA写入,内核并没有监控数据包写入情况,这时候NIC触发一个硬中断,每一个硬件中断会对应一个中断号,且指定一个vCPU来处理. 3: 硬件中断的中断处理程序,调用驱动程序完成,然后启动软中断 4: 硬中断触发的驱动程序会禁用网卡硬中断(不会停止数据的拷贝,会正常持续的拷贝) 5: 硬中断触发的驱动程序会启动软中断,启用软中断目的是将数据包后续处理流程交给软中断慢慢处理,这个时候退出硬件中断了,但是注意和网络有关的硬中断,要等到后续开启硬中断后,才有机会再次被触发 6: NAPI触发软中断,触发napi系统 7: 消耗ring buffer指向的skb_buffer 8: NAPI循环处理ring buffer数据,处理完成 9: 启动网络硬件中断,有数据来时候就可以继续触发硬件中断,继续通知CPU来消耗数据包其实上述过程过程简单描述为:网卡收到数据包,驱动程序关闭网卡硬中断,DMA到内核内存,中断通知内核数据有了,内核按轮次处理消耗数据包,一轮处理完成后,开启硬中断
GRO
Generic Receive Offload:将多个数据聚合在一个skb结构,然后作为一个大数据包交付给上层的网络协议栈,以减少上层协议栈处理skb的开销,提高系统接收数据包的性能
GRO是针对网络
收包流程进行改进的,并且只有NAPI类型的驱动才支持此功能1: 对于 TCP 中的 GRO, 这里内核在拼接数据包时会遵循 TCP 的语义, 比如内核在收到了三个 TCP 数据包, TCP 序号分别为 33, 34, 35, 那么此时内核会将三个TCP 数据包拼接成一个之后向上层协议传递 2: 对于UDP中的GRO,仅当 udp 数据包具有相同大小时, 才会被拼接成一个大的udp数据包, 同时内核还会告诉上层应用原始 udp 数据包的长度信息GRO 给协议栈提供了一次将包交给网络协议栈之前,对其
检查校验、修改协议头和发送应答包(ACK packets)的机会1: 如果 GRO 的 buffer 相比于包太小了,它可能会选择什么都不做 2: 如果当前包属于某个更大包的一个分片,调用 enqueue_backlog 将这个分片放到某个 CPU 的包队列。当包重组完成后,会交给 receive_skb() 方法处理 3: 如果当前包不是分片包,直接调用 receive_skb(),进行一些网络栈最底层的处理
XDP
全称:
快速数据路径(eXpress Data Path),是内核中提供的处理网络包的一个位置,能够挂载eBPF程序,对网络包进行一些较为简单的操作,它能够在网络数据包到达网卡驱动层时对其进行处理
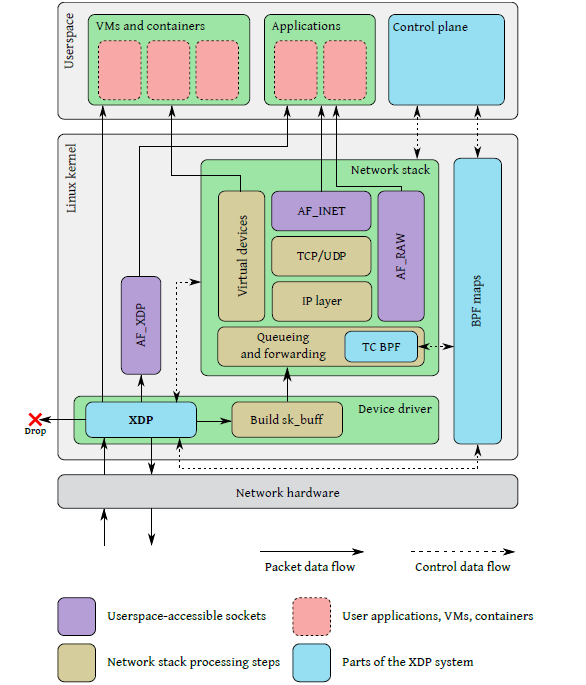
上图描绘了整个XDP系统,四个主要组成部分
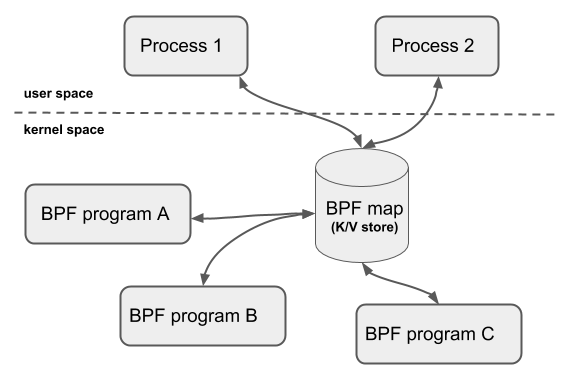
XDP driver hook:XDP 程序的主入口,在网卡收到包后执行 eBPF virtual machine:执行 XDP 程序的字节码,以及对字节码执行 JIT 以提升性能 BPF maps:内核中的 key/value 存储,作为图中各系统的主要通信通道 BPF Map本质上是以「键/值」方式存储在内核中的数据结构,它们可以被任何知道它们的BPF程序访问。在内核空间的程序创建BPF Map并返回对应的文件描述符,在用户空间运行的程序就可以通过这个文件描述符来访问并操作BPF Map(cilium 通过运行在 socket 层的 BPF 程序(cilium agent)和运行在 tc/XDP 层的 BPF 程序共享service map(其中存储了 service 及其 backend pods 的映射关系)来动态更新BPF配置) · BPF map 使 BPF 程序能与系统的其他部分之间通信 · Helpers 使 BPF 程序能利用到某些已有的内核功能(例如路由表), 而无需穿越整个内核网络栈 eBPF verifier:加载程序时对其执行静态验证,以确保它们不会导致内核崩溃
网卡收到包之后,在
处理包数据(packet data)之前,会先执行 main XDP hook 中的eBPF程序。运行的XDP程序可以通过XDP动作码来指定驱动对网络数据包的后续动作:1: XDP_ABORTED 意味着程序错误,会将数据包丢掉,与XDP_DROP不同之处在于XDP_ABORTED会用trace_xdp_exception记录错误行为,因此可以通过 tracing 工具来监控这种非正常行为 2: XDP_DROP 会在网卡驱动层直接将该数据包丢掉,无需再穿越后面复杂的协议栈消耗资源。对于 DDoS mitigation 或通用目的防火墙程序来说这尤其有用 3: XDP_PASS 会将该数据包继续送往内核的网络协议栈,当前正在处理这个包的CPU会分配一个skb,做一些初始化,然后将其送到 GRO 引擎。这是没有 XDP 时默 认的包处理行为是一样的 4: XDP_TX(Transmit) 会将该数据包从同一块网卡返回,对于实现防火墙+负载均衡的程序来说这非常有用,因为这些部署了BPF的节点可以作为一个 hairpin (发卡模式,从同一个设备进去再出来)模式的负载均衡器集群,将收到的 包在 XDP BPF 程序中重写(rewrite)之后直接发送回去 5: XDP_REDIRECT 则是将数据包重定向到其它的网卡或CPU,或者结合AF_XDP可以将数据包直接送往用户空间 a) AF_XDP是一个协议族(例如AF_NET),主要用于高性能报文处理,我们使用普通的 socket() 系统调用创建一个AF_XDP套接字(XSK) b) 每个XSK都有两个ring:RX RING 和 TX RING。套接字可以在 RX RING 上接收数据包,并且可以在 TX RING 环上发送数据包 c) RX或TX描述符环指向存储区域(称为UMEM,UMEM是一个虚拟的连续内存域,userspace可读写该区域)中的数据缓冲区,RX和TX可以共享同一UMEM Linux 内核实现了一个功能完整的路由表,作为数据平面,支持: policy routing,source-specific routing,multipath load balancing, and more` XDP通过 helper 函数,能直接在内核路由表中查询: 1: 如果查询成功,会返回 egress interface 和下一跳 MAC 地址, XDP 程序利用这些信息足够将包立即转发出去 2: 如果下一跳MAC还是未知的(因为之前还没进行过neighbour lookup),XDP程序就能将包传给内核网络栈,后者会解析neighbor地址,这样随后的包就能直接被XDP程序转发了 struct neighbour 存储邻居(指的是和本机相邻只有一跳的机器)相关信息,该结构描述主机的L3地址,主机有多个L3地址也就有多个该结构可在系统
/usr/src/linux-headers-5.4.0-124/include/uapi/linux/bpf.h查看对应定义的状态码,你得看下自己的内核版本enum xdp_action { XDP_ABORTED = 0, XDP_DROP, XDP_PASS, XDP_TX, XDP_REDIRECT, };XDP 程序典型执行流:
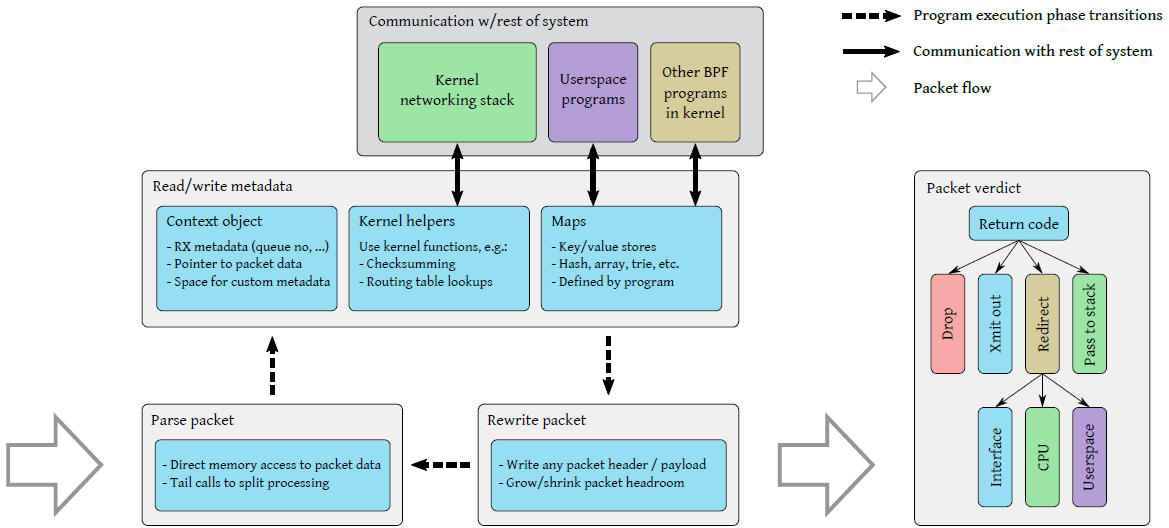
网卡收到一个包时,XDP 程序依次执行(
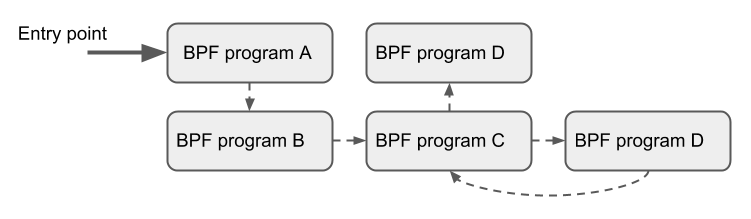
读取包数据、处理元数据、重写包数据):1:提取包头中的信息(例如 IP、MAC、Port、Proto 等) 执行到程序时,系统会传递给它一个上下文对象(context object),其中包括了指向原始包数据的指针,以及描述信息等元数据字段 2:读取或更新一些资源的元信息(例如更新统计信息) a)解析包数据之后,XDP 程序可以读取 ctx 中的包元数据(packet metadata) 字段,例如从哪个网卡的哪个接口收上来的(ifindex)。除此之外,ctx 对象还允许 程序访问与包数据相邻的一块特殊内存区域(cb, control buffer), 在包穿越整个系统的过程中,可以将自定义的数据塞在这里 b)除了 per-packet metadata,XDP 程序还可以通过 BPF map 定义和访问自己的持久数据 ,以及通过各种 helper 函数访问内核基础设施 3:如果有需要,对这个包进行 rewrite header 操作 a) 程序能修改包数据的任何部分,包括添加或删除包头。这使得 XDP 程序能执行封装/解封装操作,以及重写(rewrite)地址字段然后转发等操作 b) 内核 helper 函数各有不同用途,例如修改一个包之后,计算新的校验和(checksum) 4: 进行最后的判决(verdict),确定接下来对这个包执行什么操作,也就是上面所描述的xdp动作码 程序还能通过尾调用(tail call),将控制权交给另一个 XDP 程序
到这里,我们顺便看一下cilium ebpf是如何用ebpf实现容器网络方案的:
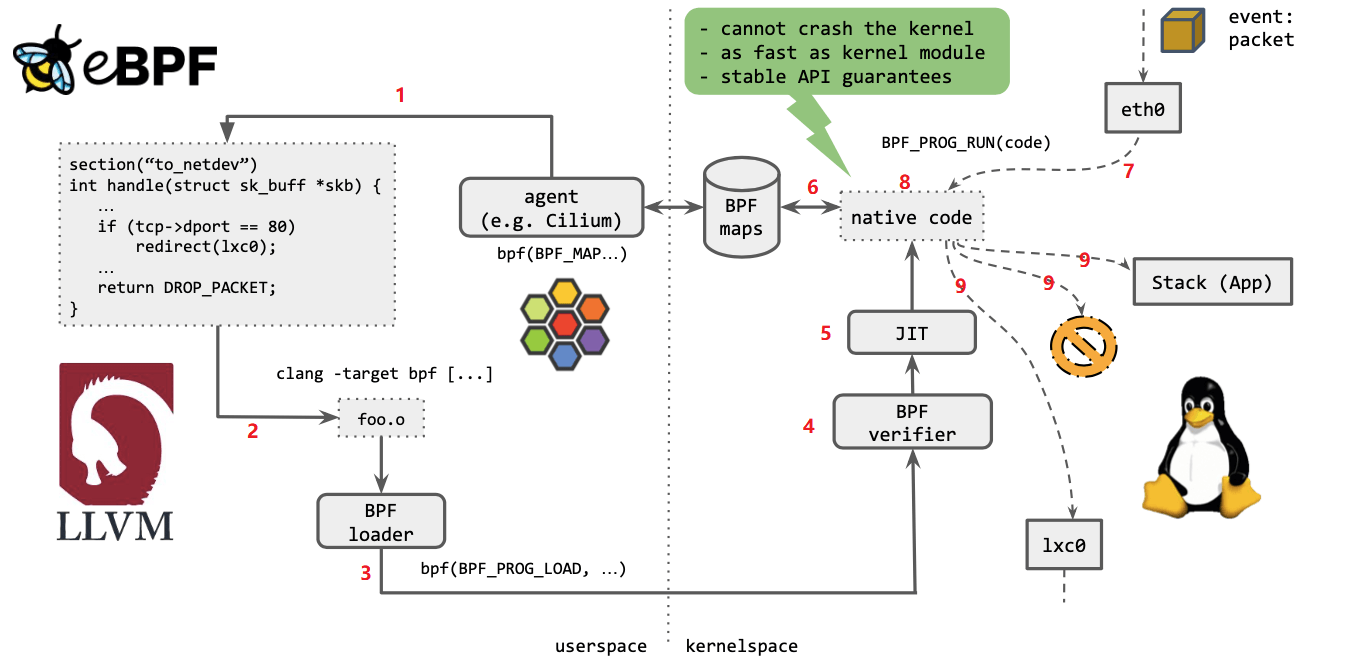
如上图所示,几个步骤:
1. Cilium agent 生成 eBPF 程序 2. 用 LLVM 编译 eBPF 程序,生成 eBPF 对象文件(object file,.o) 3. 用 eBPF loader 将对象文件加载到 Linux 内核 4. 校验器(verifier)对 eBPF 指令会进行合法性验证,以确保程序是安全的,例如 ,无非法内存访问、不会 crash 内核、不会有无限循环等 5. 对象文件被即时编译(JIT)为能直接在底层平台(例如 x86)运行的 native code 6. 如果要在内核和用户态之间共享状态,BPF 程序可以使用 BPF map(上面介绍过) 7. BPF 程序就绪,等待事件触发其执行。对于这个例子,就是有数据包到达网络设备时,触发 BPF 程序的执行 8. BPF 程序对收到的包进行处理,例如 mangle。最后返回一个裁决(verdict)结果 9. 根据裁决结果,如果是 DROP,这个包将被丢弃;如果是 PASS,包会被送到更网络栈的 更上层继续处理;如果是重定向,就发送给其他设备
xdp类型的程序根据其运行模式的不同分别运行在receive_skb()方法前后:
XDP具有三种运行模式: 1: 原生模式(Native XDP):即驱动模式,在该模式下的XDP程序运行在网络驱动程序的接收路径上,需要网卡驱动程序的支持(10G及以上速率的大多数网卡基本都是支持的) 2: 卸载模式(Offloaded XDP):该模式会直接将XDP程序offload到网卡上,因此程序在网卡收到包时就直接在网卡进行处理,从而彻底释放主机CPU资源,相较于原生模式,具有更高的性能。目前支持的网卡似乎只有Netronome智能网卡。在这种模式中某些BPF map 类型 和 BPF 辅助函数是不能用的。BPF 校验器检测到这种情况时会直接报错,告诉用户哪些东西是不支持的。除了这些不支持的 BPF 特性之外,其它方面与 native XDP 都是一样的。 3: 通用模式(Generic XDP):该模式下的XDP程序运行于驱动之后,位于内核协议栈的主接收路径上,无需驱动支持,但性能较差,一般用于测试。对于在生产环境使用 XDP,推荐要么选择 native 要么选择 offloaded 模式。这两种模式需要网卡驱动的支持,对于那些不支持 XDP 的驱动,内核提供了 Generic XDP ,这是软件实现的 XDP,性能会低一些, 在实现上就是将 XDP 的执行上移到了内核网络栈
native/offloaded 模式
XDP 在内核收包函数
receive_skb()之前,此时内核还没有为包分配 struct sk_buff 结构体,也没有执行任何解析包的操作,图中有 Cilium logo 的地方,都是 datapath 上 Cilium 重度使用 BPF 程序的地方
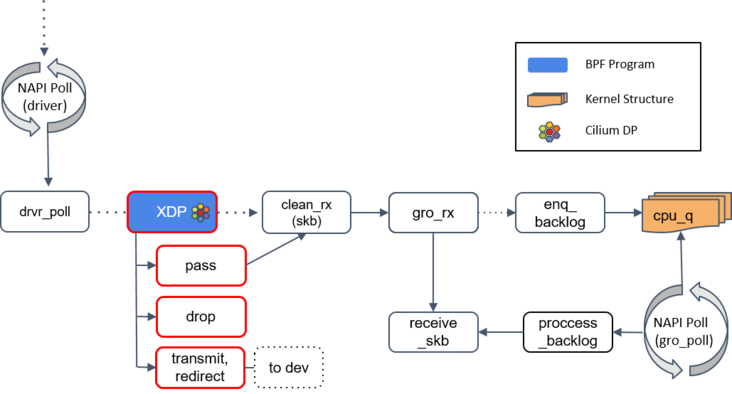
Generic XDP 模式
XDP 在内核收包函数
receive_skb()之后
如果驱动支持 XDP,那 XDP 程序将在
poll机制内执行,如果网卡不支持,那 XDP 程序将只能在更后面执行
clean_rx()
如果 XDP 返回是
PASS,内核会继续沿着默认路径处理包,到达clean_rx()方法。这个方法创建一个socket buffer(skb)对象,可能还会更新一些统计信息,对 skb 进行硬件校验和检查,然后将其交给gro_receive()方法
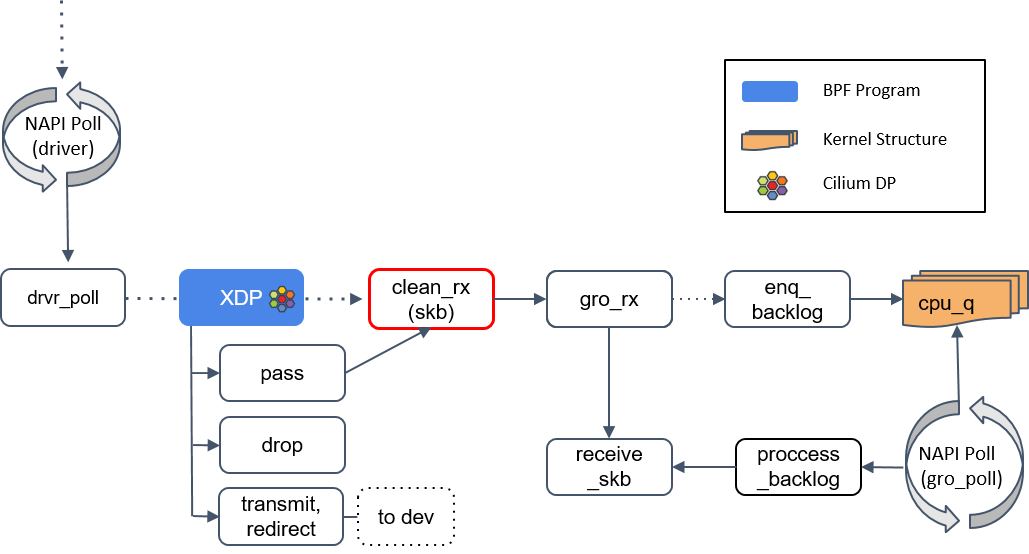
gro_receive()
将包交给网络协议栈之前,把相关的小包合并成一个大包,目的是减少传送给网络栈的包数,这有助于减少 CPU 的使用量,提高吞吐量
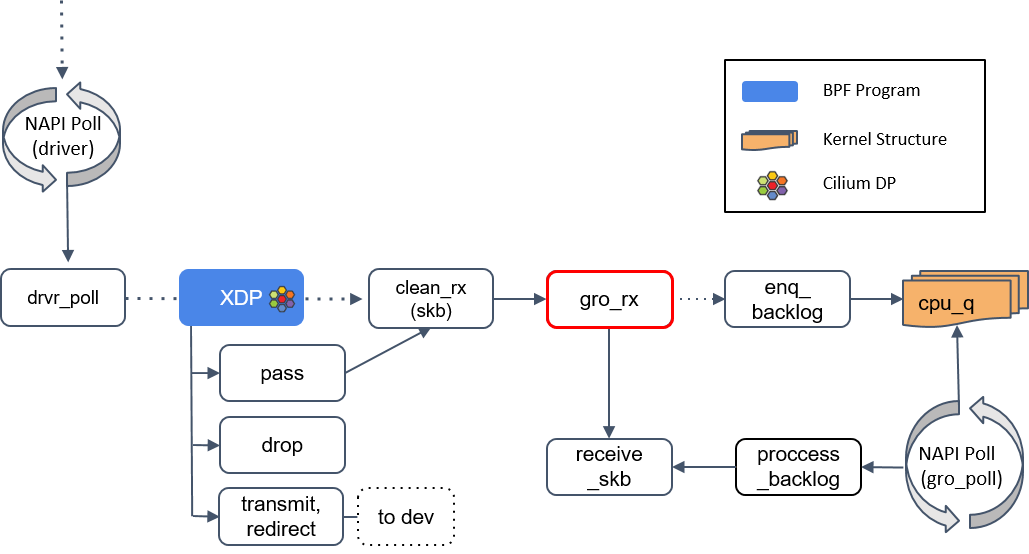
receive_skb()
图中有个
check_taps框,但其实并没有这个方法,receive_skb() 会轮询所有的socket tap,将包放到正确的 tap 设备的缓冲区
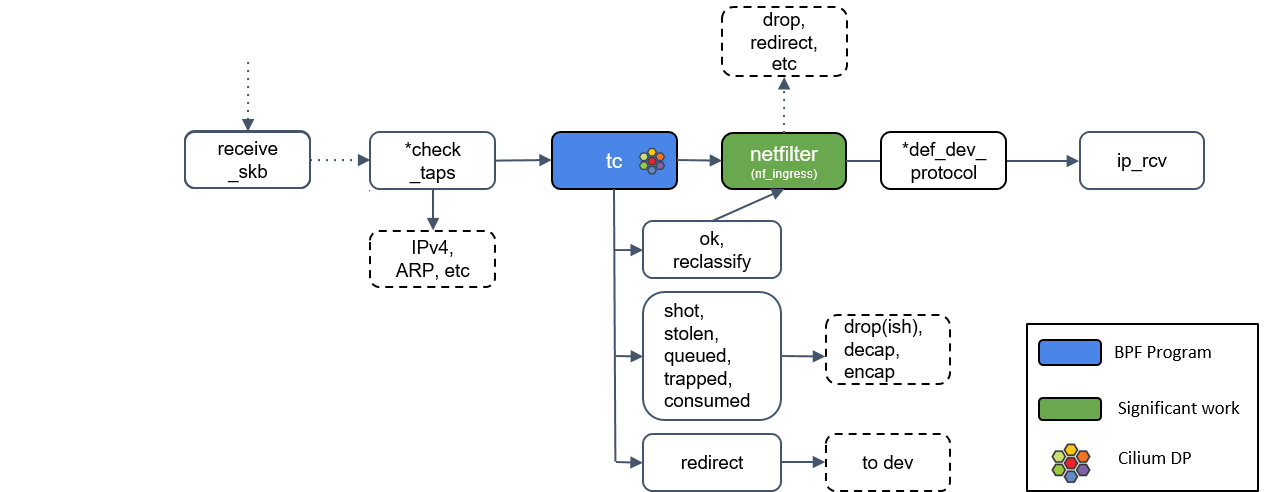
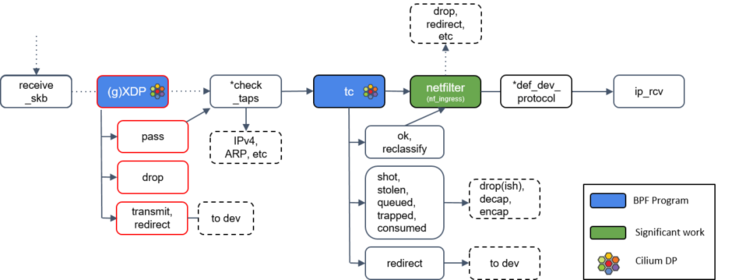
tc(traffic classifier)
流量控制器TC(Traffic Control)用于Linux内核的
流量控制,它利用队列规定建立处理数据包的队列,并定义队列中的数据包被发送的方式, 从而实现对流量的控制(调度网络包的延迟、丢失、传输顺序和速度控制,例如修改包(mangle,给 skb 打标记)、重路由(reroute)、丢弃包(drop))Cilium 控制的网络设备,至少被加载了一个 tc eBPF 程序
TC主要包括三个基本要素:
1: qdisc:队列规则,TC的核心,用于确定数据包的发送方式。如下命令实现了指定的eth0网卡上所有的包固定加了200ms延时 # tc qdisc add dev eth0 root netem delay 200ms 2: class和filter:类和过滤器。类即是数据流量的类别,各种应用和终端的流量通过filter进行分类,进入到队列规则里排队进行发送。如下命令行所示即通过class和filter实现了对指定ip的限速,其它弱网类似: # tc class add dev eth0 parent 1:1 classid 1:2 htb rate 500kbit # tc filter add dev eth0 protocol ip parent 1:0 prio 3 u32 match 192.168.2.10 flowid 1:3 其它常用到的弱网场景: 延迟波动,如下命令表示延迟为时延150ms-250ms波动(由于网卡上发出的包延迟不同,所以会有一定程度的乱序发生): # tc qdisc add dev eth0 root netem delay 200ms 50ms 乱序,如下代表随机丢包30% # tc qdisc add dev eth0 root netem delay 50ms reorder 25% 随机丢包,如下代表随机丢包30% # tc qdisc add dev eth0 root netem loss 30%和 XDP 一样,TC 的输出代表了数据包如何被处置的一种动作,最新的 Linux 内核中定义的有 9 种动作:
/usr/src/linux-headers-5.4.0-124/include/uapi/linux/pkt_cls.h#define TC_ACT_UNSPEC (-1) #define TC_ACT_OK 0 #define TC_ACT_RECLASSIFY 1 #define TC_ACT_SHOT 2 #define TC_ACT_PIPE 3 #define TC_ACT_STOLEN 4 #define TC_ACT_QUEUED 5 #define TC_ACT_REPEAT 6 #define TC_ACT_REDIRECT 7 #define TC_ACT_TRAP 8上面我们会发现定义了一个
TC_ACT_UNSPEC,这表示使用 tc 的默认 action(与 classifier/filter 返回-1时类似),你要是想详细的了解tc的工作原理,点击此处进行阅读学习
Netfilter
Netfilter是Linux内核中的一个
数据包处理模块,位于网卡和内核协议栈之间的一堵墙,它可以提供数据包的过滤、转发、地址转换NAT功能,被广泛用于网络层和数据链路层等,大家熟悉的iptables就是用来在Netfilter中增加、修改、删除数据包处理规则
我们来看一张经典的Netfilter 中网络数据包的流向图,我们可以看到,不管是链路层还是网络层,都会调用netfilter对数据进行数据
ebtables 主要用来处理数据链路层数据 iptales 主要用来处理网络层和传输层数据如果 tc BPF 返回 OK,包会再次进入 Netfilter,Netfilter 也会对入向的包进行处理

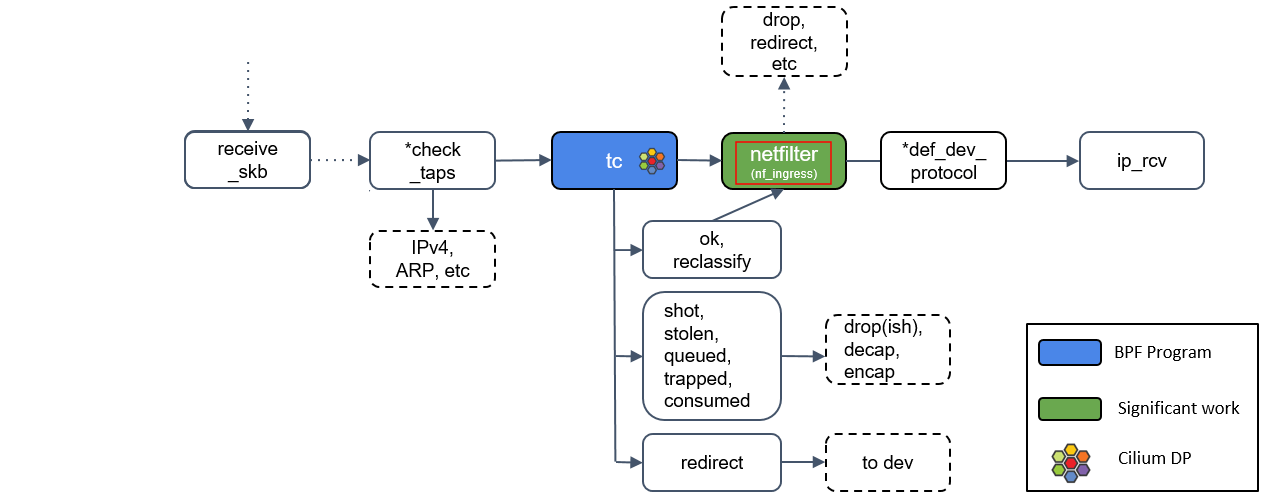
ip_rcv()
如果包没有被前面丢弃,就会通过网络设备的 ip_rcv() 方法进入协议栈的三层( L3)—— 即 IP 层 —— 进行处理
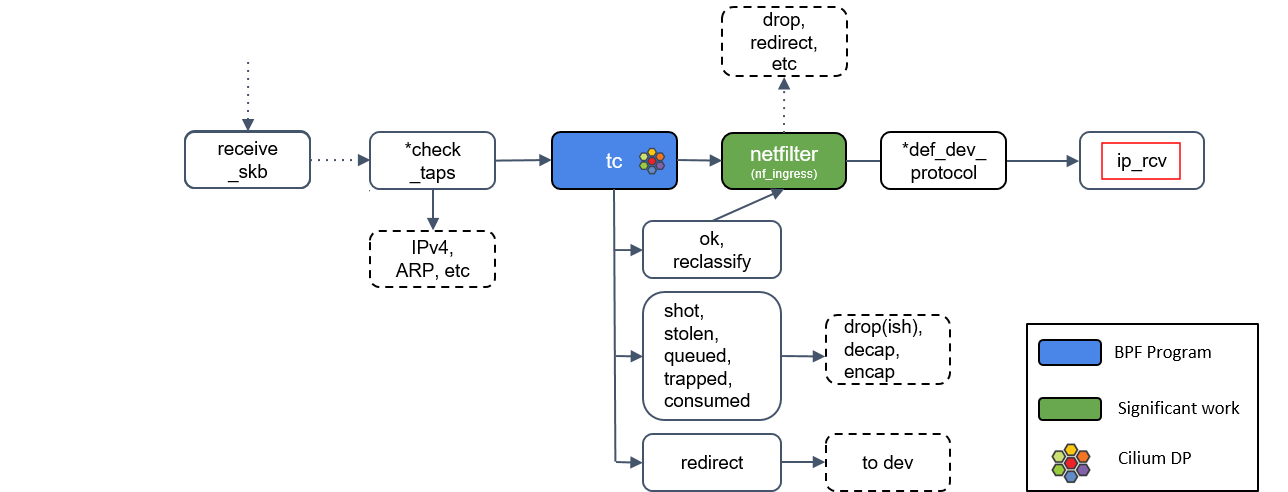
netfilter L4 处理
ip_rcv() 做的第一件事情是再次执行 Netfilter 过滤,因为我们现在是从四层(L4)的视角来处理 socket buffer,因此,这里会执行 Netfilter 中的任何四层规则(L4 rules )
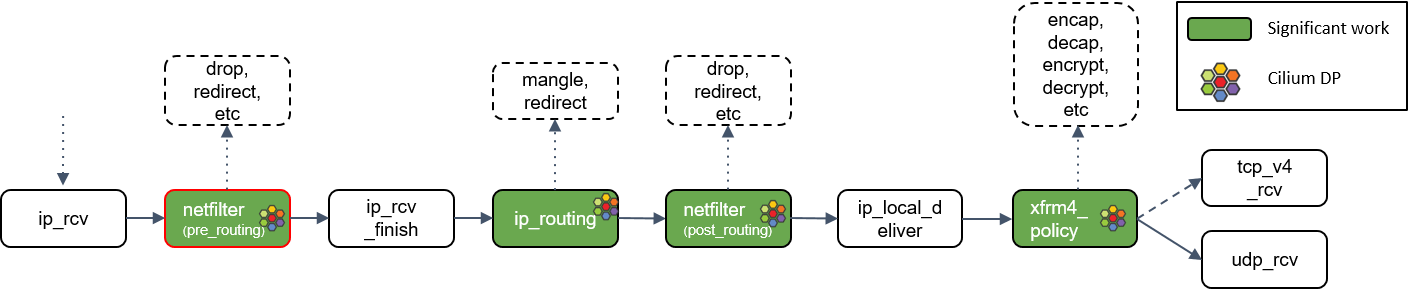
ip_rcv_finish() 处理
Netfilter 执行完成后,调用回调函数 ip_rcv_finish()
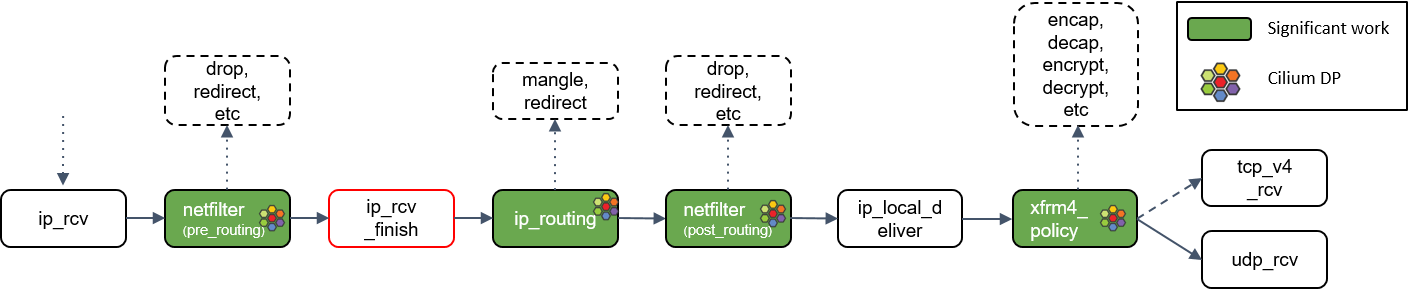
ip_routing() 处理
ip_routing() 对包进行路由判断,例如看它是否是在 lookback 设备上,是否能路由出去(egress),或者能否被路由,能否被 unmangle 到其它设备等
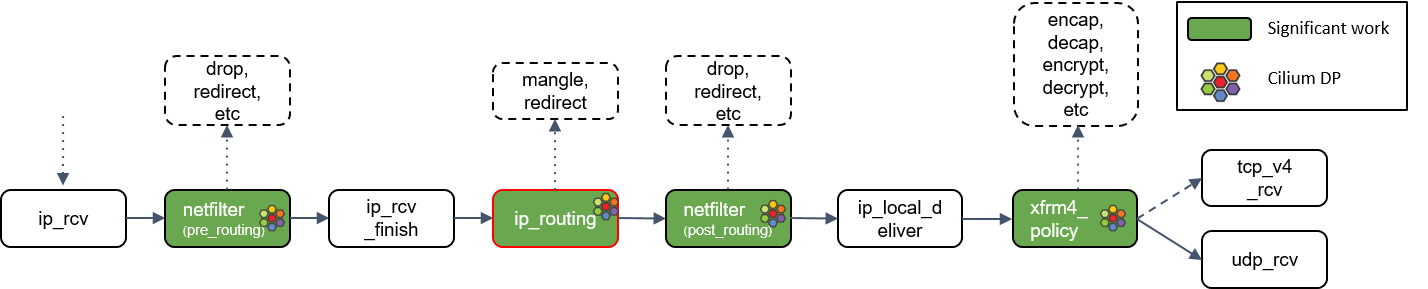
ip_local_deliver()
根据路由判断的结果,如果包的目的端是本机,会调用 ip_local_deliver() 方法
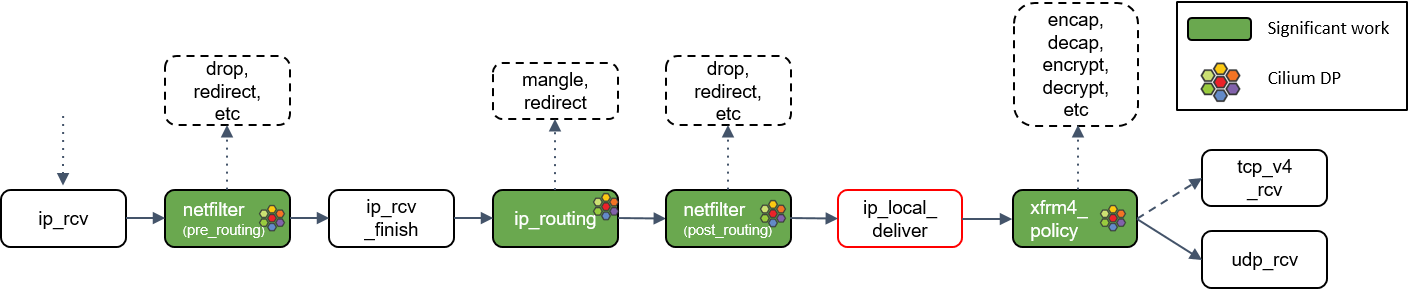
xfrm4_policy()处理
xfrm4_policy() 完成对包的封装、解封装、加解密等工作。例如,IPSec 就是在这里完成的
最后,根据四层协议的不同,ip_local_deliver() 会将最终的包送到 TCP 或 UDP 协议 栈。这里必须是这两种协议之一,否则设备会给源 IP 地址回一个 ICMP destination unreachable 消息
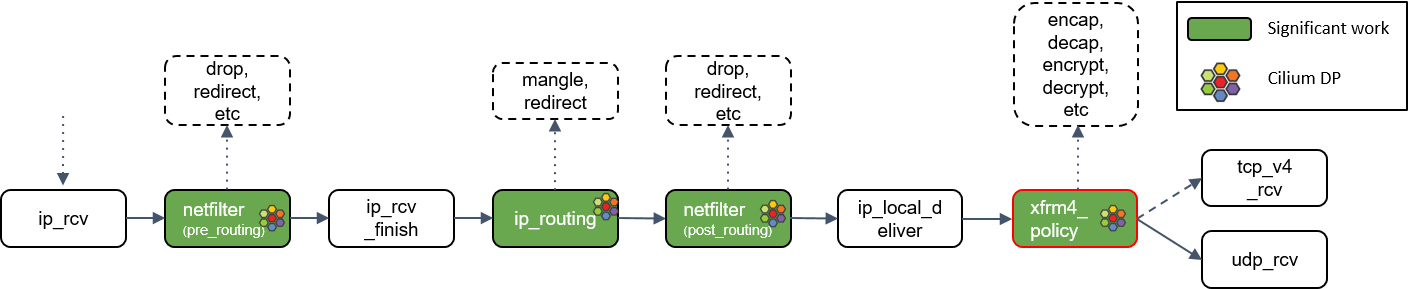
udp_rcv()处理
此处拿 UDP 协议作为例子,因为 TCP 状态机太复杂了,不适合这里用于理解 datapath 和数据流
udp_rcv() 对包的合法性进行验证,检查 UDP 校验和。然后,再次将包送到 xfrm4_policy() 进行处理
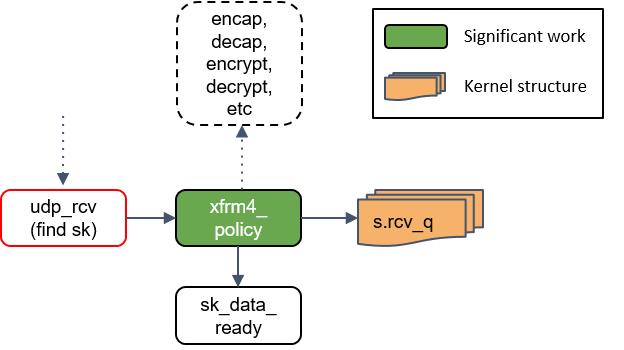
xfrm4_policy()再次处理
这里再次对包执行 transform policies 是因为,某些规则能指定具体的四层协议,所以只 有到了协议层之后才能执行这些策略
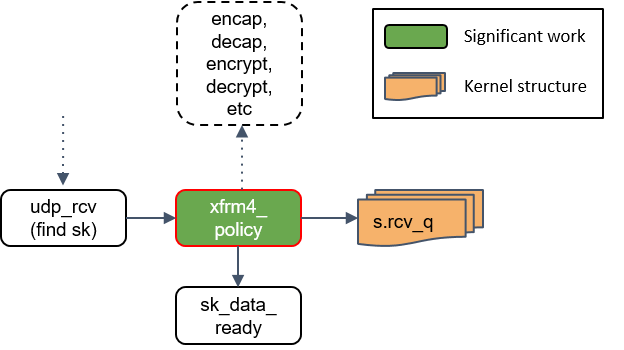
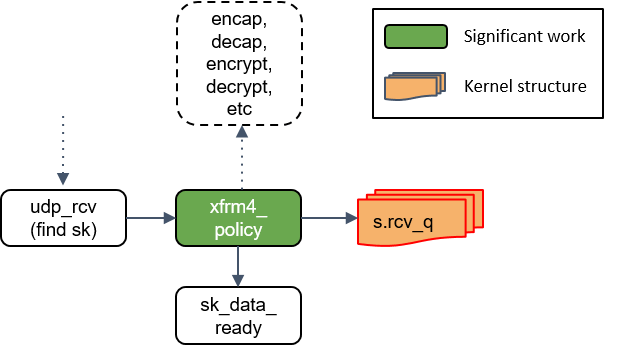
将包放入socket_receive_queue
这一步会拿端口(port)查找相应的 socket,然后将 skb 放到一个名为 socket_receive_queue 的链表
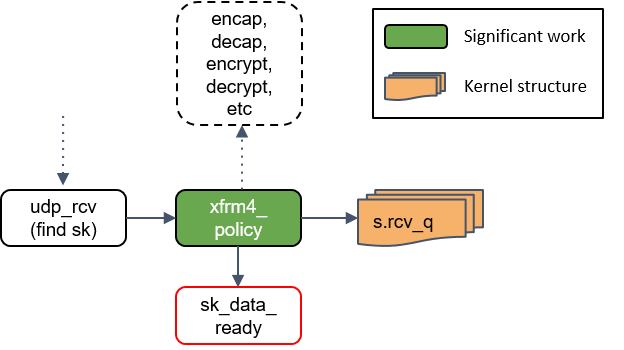
通知socket收数据:sk_data_ready()
最后,udp_rcv() 调用 sk_data_ready() 方法,标记这个 socket 有数据待收
本质上,一个 socket 就是 Linux 中的一个文件描述符,这个描述符有一组相关的文件操 作抽象,例如 read、write 等等
我们可以看到整个过程中,多个地方都可以进行数据包的转发,以上过程就是从硬件到内核再到应用程序的过程,我们再来看下cilium中数据是如何进入pod内的。
比对kube-proxy
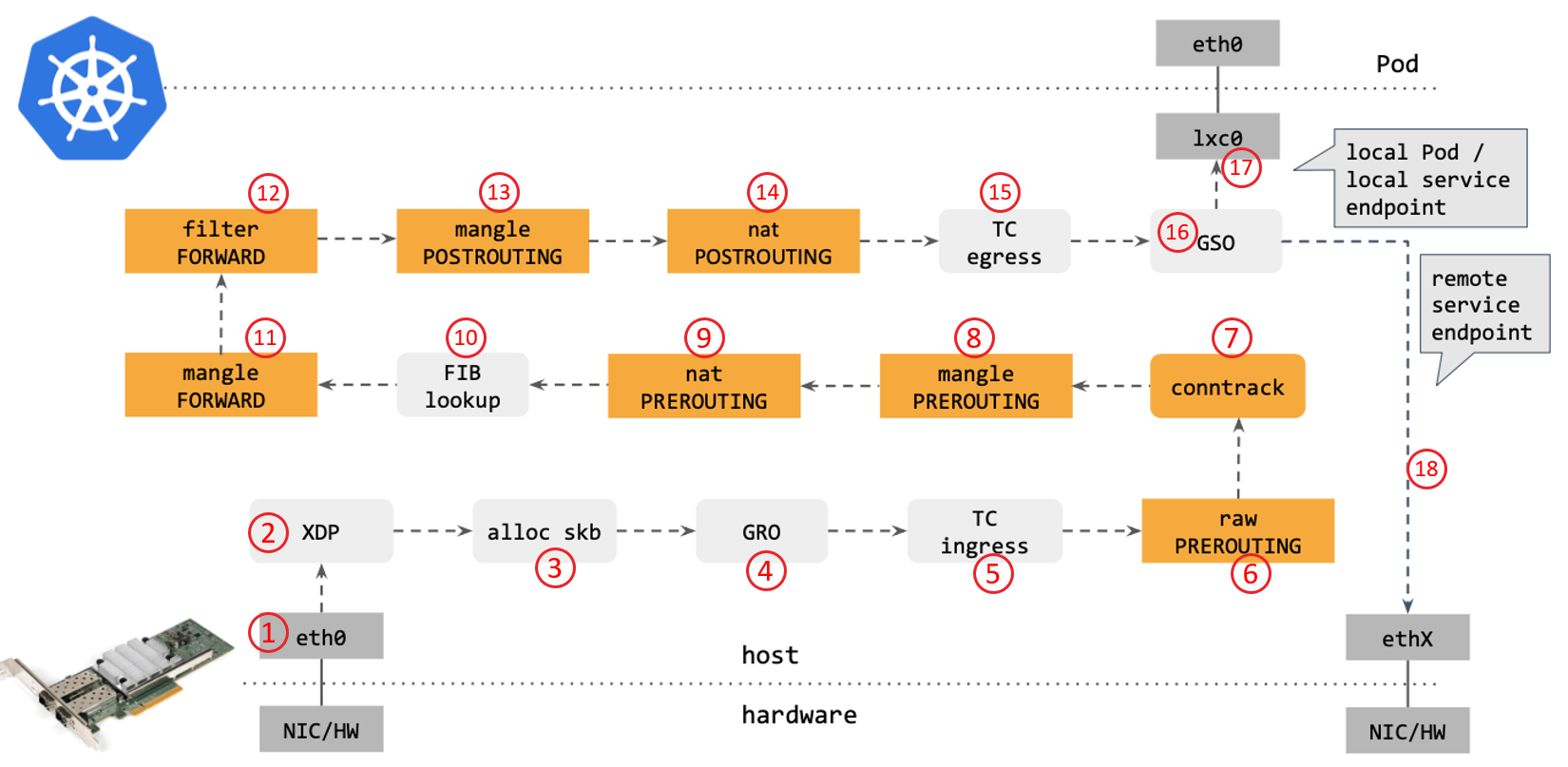
从网络角度看,使用传统的 kube-proxy 处理 Kubernetes Service 时,包在内核中的转发路径:
步骤如下:
1. 网卡收到一个包(通过 DMA 放到 ring-buffer) 2. 包经过 XDP hook 点 3. 内核给包分配内存,此时才有了大家熟悉的 skb(包的内核结构体表示),然后送到内核协议栈 4. 包经过 GRO 处理,对分片包进行重组 5. 包进入 tc(traffic control)的 ingress hook,接下来,所有橙色的框都是 Netfilter 处理点。 6. Netfilter:在 PREROUTING hook 点处理 raw table 里的 iptables 规则 7. 包经过内核的连接跟踪(conntrack)模块 8. Netfilter:在 PREROUTING hook 点处理 mangle table 的 iptables 规则 9. Netfilter:在 PREROUTING hook 点处理 nat table 的 iptables 规则 10. 进行路由判断(FIB:Forwarding Information Base,路由条目的内核表示,译者注) ,接下来又是四个 Netfilter 处理点 11. Netfilter:在 FORWARD hook 点处理 mangle table 里的 iptables 规则 12. Netfilter:在 FORWARD hook 点处理 filter table 里的 iptables 规则 13. Netfilter:在 POSTROUTING hook 点处理 mangle table 里的 iptables 规则 14. Netfilter:在 POSTROUTING hook 点处理 nat table 里的 iptables 规则 15. 包到达 TC egress hook 点,会进行出方向(egress)的判断,例如判断这个包是到本 地设备,还是到主机外 16. 对大包进行分片。根据 step 15 判断的结果,这个包接下来可能会: 发送到一个本机 veth 设备,或者一个本机 service endpoint,或者,如果目的 IP 是主机外,就通过网卡发出去我们再来看下cilium ebpf包转发路径(tc模式):
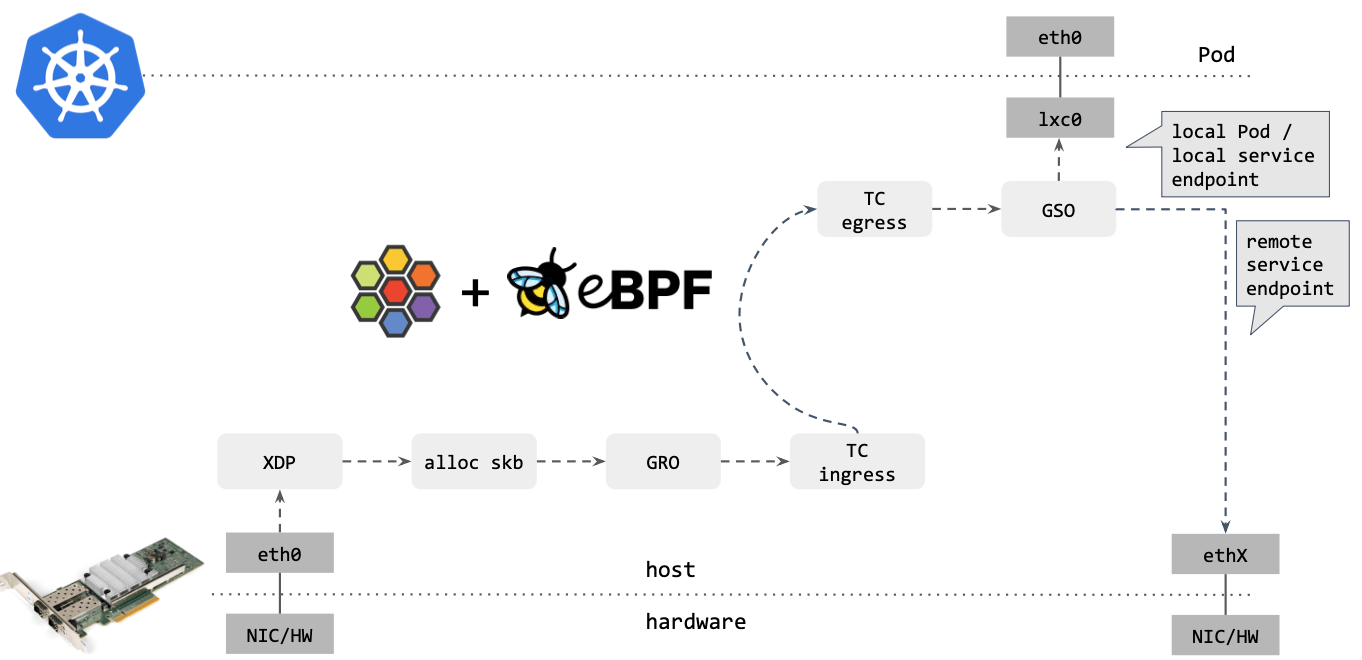
对比可以看出,Cilium eBPF datapath 做了短路处理:从 tc ingress 直接 shortcut 到 tc egress,节省了 9 个中间步骤(总共 17 个),更重要的是:这个 datapath 绕过了 整个 Netfilter 框架(橘黄色的框们),去掉那些不用的框之后,Cilium eBPF datapath 长这样:
图中我们可以看到,在不同节点间包的转发是完全不经过netfilter的
如果包的目的端是另一台主机上的 service endpoint,那你可以直接在 XDP 框中完成包的重定向(收包
1->2,在步骤2中对包 进行修改,再通过2->1发送出去),将其发送出去,如下图所示(XDP模式):
可以看到,这种情况下包都没有进入内核协议栈(准确地说,都没有创建 skb)就被转 发出去了,性能可想而知
我们可以看到在以上讲解的内核的datapath中,简单地介绍了协议栈每个位置(Netfilter、iptables、eBPF、XDP)能执行的动作,这些位置提供的处理能力也是不同的。例如:
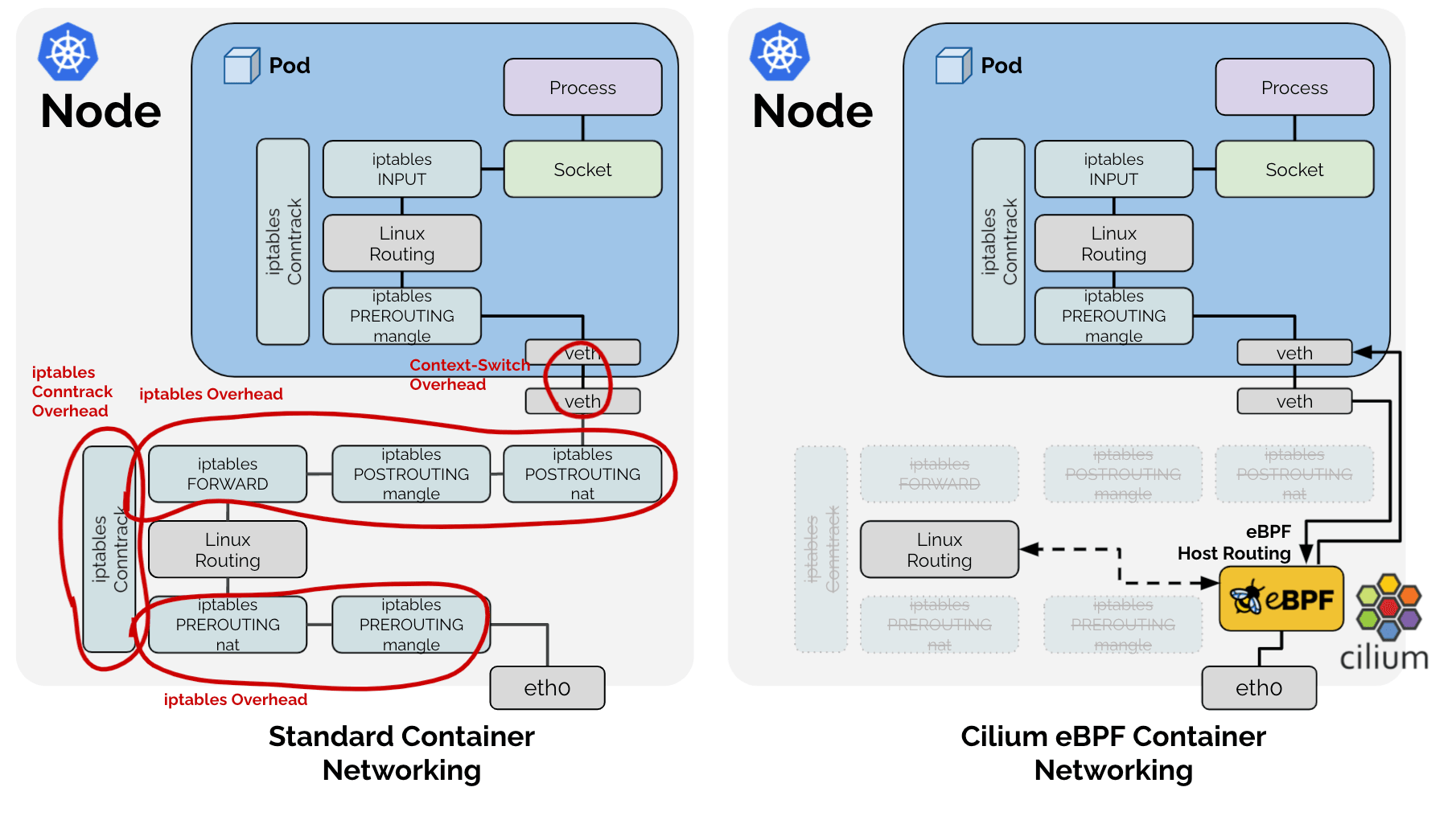
1: XDP 可能是能力最受限的,因为它只是设计用来做快速丢包(fast dropping)和 非本地重定向(non-local redirecting) 但另一方面,它又是最快的程序,因为 它在整个 datapath 的最前面,具备对整个 datapath 进行短路处理(short circuit the entire datapath)的能力 2: tc 和 iptables 程序能方便地 mangle 数据包,而不会对原来的转发流程产生显着影响我们再来看一下以下两张图(传统模式和cilium的主机路由模式kernel>=5.10):
我们也可以清楚的看到,在数据包进入pod的时候,绕过了所有的iptables和上层的堆栈开销(在Calico eBPF中,也对 iptables做了一些绕过),更多cni的测试,可以点击此处进行了解。(图中也可以看到在与应用进行数据交互的时候,经过了netfilter框架,也就是上面所描述的那些过程)


以上就是 Cilium 基于 eBPF 的内核收包之旅,理解这些东西非常重要,因为这是 Cilium 乃至广义 datapath 里非常核心的东西。如果遇到底层网络问题,或者需要做 Cilium/kernel 调优,那你必须要理解包的收发/转发路径。我们了解其过程之后就可以直接使用cilium替代kube-proxy和flannel(calico)来测试使用了
参考文章
https://cilium.io/blog/2021/05/11/cni-benchmark/#ebpfhostrouting
https://zhuanlan.zhihu.com/p/452612386
https://segmentfault.com/a/1190000041728472
https://blog.csdn.net/wangquan1992/article/details/117302658
http://arthurchiao.art/blog/understanding-ebpf-datapath-in-cilium-zh/
https://arthurchiao.art/blog/xdp-paper-acm-2018-zh/
https://blog.csdn.net/wyttRain/article/details/113972282
https://zhuanlan.zhihu.com/p/101662799